

Falcon 180B Shows That Open Models Can Rival Performance of Leading Proprietary LLMs
Another model challenges the performance leaders by leveraging more data tokens


The Technology Innovation Institute (TII) has released the Falcon 180B large language model (LLM), a successor to its 40B foundation model released earlier this year, and it debuted atop the Open LLM Leaderboard for “open models.” Notably, tests show Falcon 180B exhibits similar performance as Google’s PaLM Large LLM.
TII revealed that over 12 million developers had tried Falcon 40B, and it is expecting many of those to experiment with 180B because of its performance advantage. According to a blog post on Hugging Face welcoming the new LLM to the platform:
In terms of capabilities, Falcon 180B achieves state-of-the-art results across natural language tasks. It tops the leaderboard for (pre-trained) open-access models and rivals proprietary models like PaLM-2. While difficult to rank definitively yet, it is considered on par with PaLM-2 Large, making Falcon 180B one of the most capable LLMs publicly known.
Surpassing Llama 2 Too
In addition, Falcone 180B also surpassed Meta’s Llama 2 in recent tests. “With 68.74 on the Hugging Face Leaderboard, Falcon 180B is the highest-scoring openly released pre-trained LLM, surpassing Meta’s LLaMA 2 (67.35),” said the Hugging Face blog. The new model also handily outperforms its predecessor Falcon 40B’s score of 60.4.
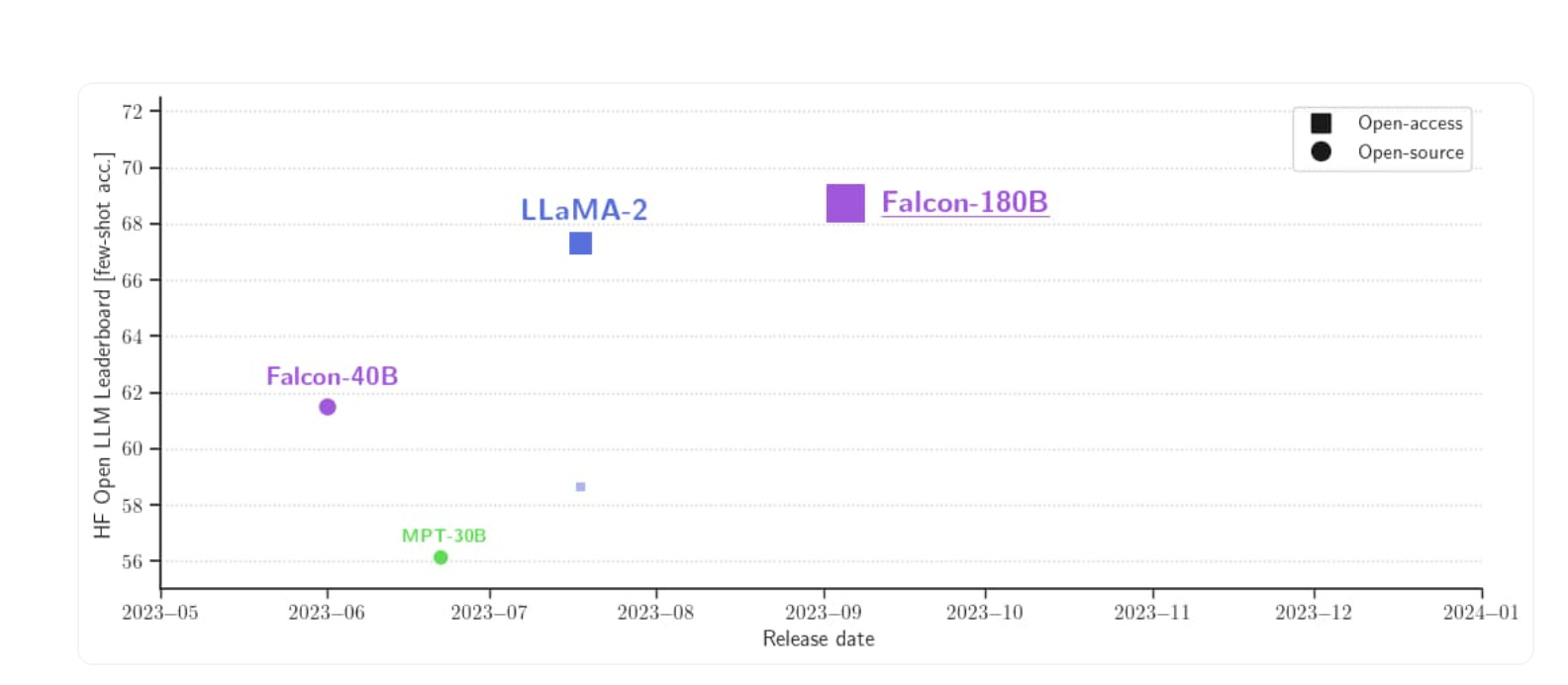
How is 180B Different?
Falcon 180B is a 180 billion parameter model trained on 3.5 trillion data tokens. The Falcon 40B is over 70% smaller in terms of both parameters and training data. Llama 2’s largest model has 70 billion parameters and was trained on 2 trillion data tokens.
There is no official statement about Google’s PaLM 2 model parameter size, but CNBC reported it was trained on 3.6 trillion tokens. A technical report on the PaLM 2 models confirms it has fewer parameters than the 540 billion parameter PaLM. The report highlights why training with more data is in vogue.
The largest model in the PaLM 2 family, PaLM2-L, is significantly smaller than the largest PaLM model but uses more training compute. Our evaluation results show that PaLM 2 models significantly outperform PaLM on a variety of tasks, including natural language generation, translation, and reasoning. These results suggest that model scaling is not the only way to improve performance. Instead, performance can be unlocked by meticulous data selection and efficient architecture/objectives. Moreover, a smaller but higher quality model significantly improves inference efficiency, reduces serving cost, and enables the model’s downstream application for more applications and users.
There is a clear trend toward more data that is also more highly curated data among the leading LLM developers. TII chose to significantly increase model parameter size and training data for 180B, as well as training hours. Some combination of those factors has led to improved performance.
What About the License?
The Hugging Face blog post includes an interesting disclaimer:
‼️ Commercial use: Falcon 180b can be commercially used but under very restrictive conditions, excluding any "hosting use". We recommend to check the license and consult your legal team if you are interested in using it for commercial purposes.
It is a custom license that is actually royalty-free unless you intend to host it for others. Companies that want to host Falcon 180B “3.2. Other than where you are a Hosting User in accordance with Section 9, Your patent license to use the Work shall be royalty free and without charge,” according to the terms. This appears to include any cloud-based hosting along with SaaS companies that provide a feature driven by the model.
How the Cloud Hyperscalers are Shaping the Generative AI Market

Large language models (LLM) or foundation models, if you prefer, receive a lot of attention today. On the surface, it seems like a pitched battle between LLM providers to capture new users and use cases. That is true, to a degree. However, another way to look at the market is that the LLM wars exist in the larger context of the cloud computing wars.
Falcon-40B LLM, Trained on 1 Trillion Data Tokens, Knocks LLaMA from Open-Source LLM Top Spot

There’s a new large language model (LLM) leader on the Open LLM Leaderboard hosted by Hugging Face. Falcon-40B from the Technology Innovation Institute (TII) is a 40 billion parameter LLM trained on 1 trillion data tokens of the Falcon RefinedWeb. Meta’s LLaMA-65B model and a variant called LLaMA-30B-Supercot have been at the top of the leaderboard for …