



GPT-4 Beats MedPaLM 2 for Medical Questions - Prompt Engineering vs Fine-Tuning Battle Royale
The Emerging Battle Between Large Generalist and Specialty AI Models

To Prompt or to Tune: That is the Question
Microsoft researchers published data showing the generalist foundation model GPT-4, combined with advanced prompt engineering techniques, outperformed the fine-tuned specialty AI model MedPaLM 2 in a series of tests on medical knowledge.
Since fine-tuning and model training are time-consuming and expensive, the findings suggest that applying more effective prompt engineering to the leading generalist foundation models may be a better path to more accurate results.
Microsoft’s Medprompt approach combines several prompt engineering techniques to outperform MedPaLM 2, including GPT- 4-generated chain-of-thought reasoning and generating multiple responses that are scored separately before the top answer is returned to the user.
This approach will increase the cost of inference because more tokens are generated, and it is unclear whether a small percentage gain in accuracy is worth the additional expense.
However, the results also suggest that domain-customized models should be benchmarked against generalist models such as GPT-4 combined with advanced prompt-engineering techniques to assess state-of-the-art performance.
A group of Microsoft Researchers has published a new report called “Can Generalist Foundation Models Outcompete Special Purpose Tuning? Case Study in Medicine.” The answer to the question appears to be yes, at least when your general-purpose generative AI model is GPT-4 combined with advanced prompt engineering techniques.
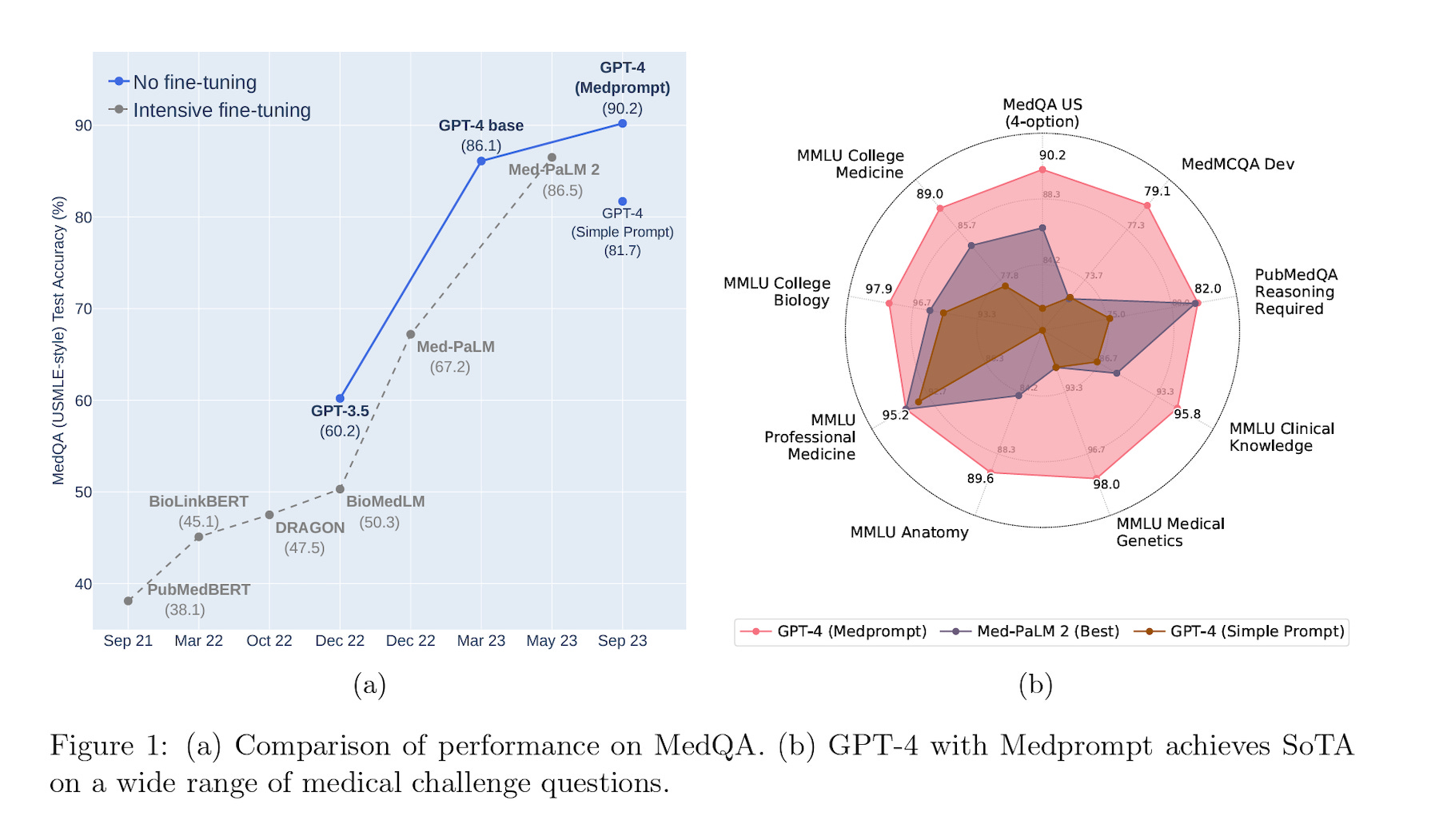
You can see from the diagrams above that GPT-4 (base), without any special prompting, nearly matches MedPaLM 2, and GPT-4 with the specialized MedPrompt outpaces the specialty model. In fact, the chart on the right shows significantly higher performance on tests other than MMLU Professional Medicine. MedPaLM 2 is a fine-tuned version of Google’s PaLM 2 model based on a curated dataset of medical knowledge. The implications here could be significant.
From a practical standpoint, anyone deploying a domain-expertise generative AI solution should consider how far they can improve model accuracy before shifting to fine-tuning or custom model training. They should also consider how advanced prompt engineering techniques, such as model-generated prompts and ensemble scoring, might further improve their fine-tuned or custom models. Granted, this all comes with a cost, even if that cost is less than fine-tuning and model training.
Testing Approach
The researchers used a series of tests in the MultiMedQA dataset. These include MedQA (medical licensing exam questions), MedMCQA (two Indian medical school entrance exams), PubMedQA (biomedical research questions), and MMLU (a suite of multi-domain tests in STEM, humanities, and social sciences). The approach was further assessed based on two nursing datasets.
It is worth noting that these tests are all multiple-choice answers. These tests are used as a proxy for accurately answering medical domain questions that, in real-world use, would be delivered in free-form text responses. Additional testing of free-form questions and answers may yield different results.
Still, the Medprompt approach is interesting. It is not a single technique but rather a combination of multiple techniques building up from zero-shot and 5-shot techniques to GPT-4 self-generated chain-of-thought (CoT) prompts to nearest neighbor 5-shot responses that are scored for a best-answer response.

The GPT self-generated CoT is interesting because it involves asking GPT-4 to generate the chain of thought prompt based on the objective. This proved to be superior to the “expert-crafted” prompt from Med-PaLM 2. The GPT-4 generated prompts offered better results and “finer-grained step-by-step reasoning logic.” Researchers suggested this may be caused by the model's better understanding of how it interprets CoT. It may also be able to better generalize CoT prompts than human experts who have implicit biases and typically are only looking at a subset of the data.
This conclusion, of course, is specific to GPT-4. The researchers do not provide evidence of whether a PaLM-generated prompt would be superior to the prompt crafted by domain experts. So, generalizing this may not be appropriate. What the research concludes is specific to GPT-4, which may have important differences from other generalist foundation models.
The ensemble approach is also particularly interesting. Instead of asking a single question and hoping for the single best answer, the approach involves splitting the question into five related examples, responding to each, and then algorithmically calculating which of the responses is most likely to predict the correct result. The introduction of multiple responses should increase the likelihood that a “hallucination” is thrown out and a “correct” answer returned.
Of course, the downside of both the CoT and ensemble techniques is the generation of additional tokens at the input and output stages, respectively. The study does not speak to the impact on latency and only indirectly considers cost. More steps will invariably increase the time for a response. A key question will be whether the added latency is meaningful. The cost is a different matter, given the linear cost curve of token production.
Broader Application
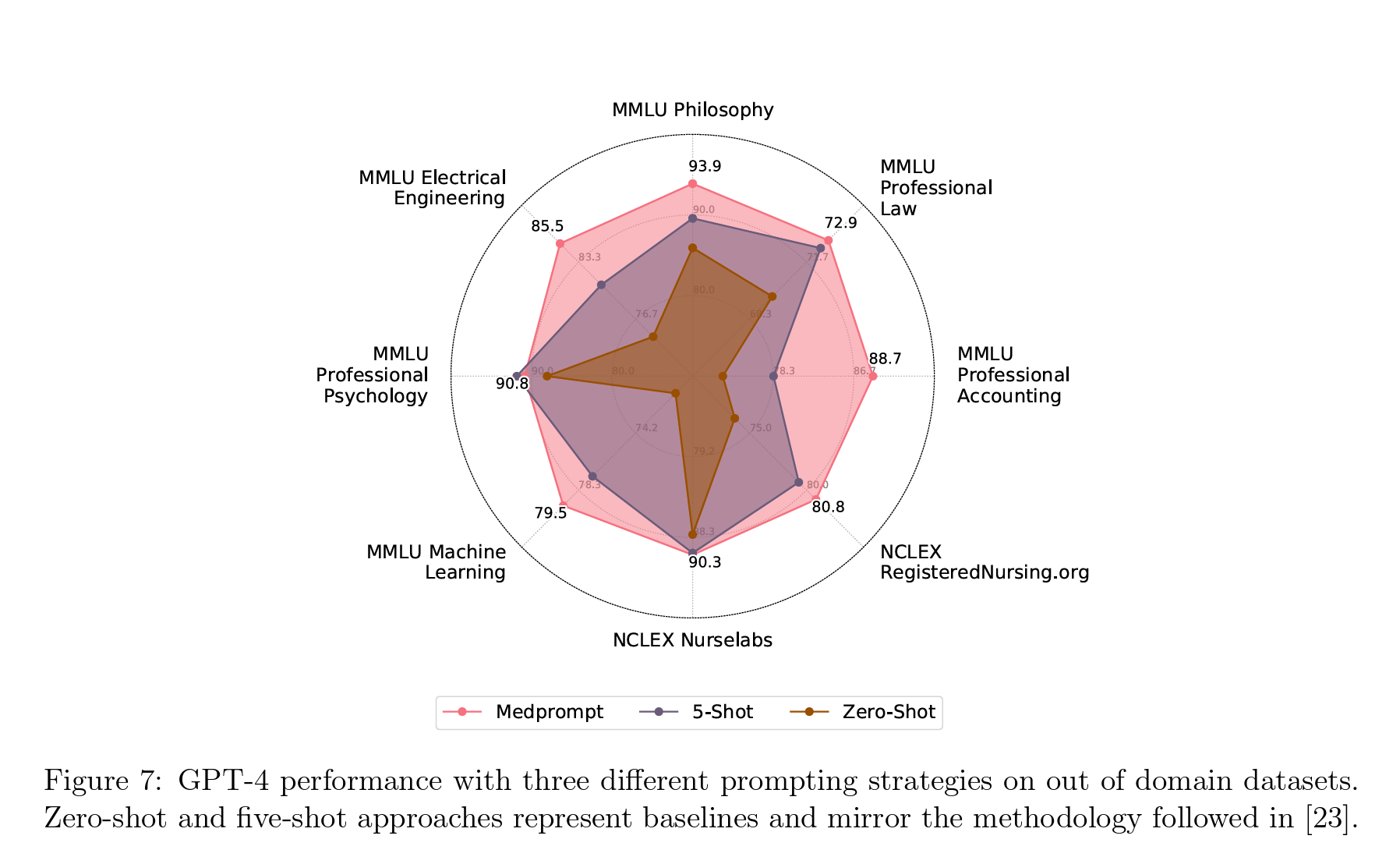
After completing the medical domain tests, the researchers applied the same prompt engineering technique to several other professional domain datasets and found similar performance improvements. This did not compare results to MedPaLM 2 but to alternative techniques. According to the study authors:
We argue that the composition of prompt engineering techniques employed in Medprompt, based on a combination of dynamic few shot selection, self-generated chain of thought, and choice shuffle ensembling, have general purpose application. They are not custom-tailored to the MultiMedQA benchmark datasets. To validate this, we further tested the final Medprompt methodology on six additional, diverse datasets from the MMLU benchmark suite covering challenge problems in the following subjects: electrical engineering, machine learning, philosophy, professional accounting, professional law, and professional psychology. We further sourced two additional datasets answering NCLEX (National Council Licensure Examination) style questions, the exam required to practice as a registered nurse in the UnitedStates.
…
Across these datasets, Medprompt provides an average improvement of +7.3% over baseline zero-shot prompting. By comparison, Medprompt provided a +7.1% improvement over the same zero-shot baseline on the MultiMedQA datasets studied in this paper. We emphasize that the similarity of improvement across datasets from different distributions demonstrates the generality of the Medprompt approach. While beyond the scope of this paper, we believe the general framework underlying MedPrompt—a combination of few shot learning and chain-of-thought reasoning wrapped in an ensemble layer—can further generalize inapplicability beyond the multiple choice question/answer setting with minor algorithmic modifications.
It is no secret that prompt engineering techniques employed in user prompts or system prompts improve results. This research may suggest that there is even more performance leverage to be gained than previously thought. In addition, dataset specialization may appear to reduce noise and improve signal in responses, but so can executing better prompt engineering on generalized foundation models.
The Scourge of Inaccurate Information
Responses from large language models (LLM) are surprisingly accurate for a wide variety of topics. However, inaccuracy of responses is the key issue on everyone’s minds. The most common conversation about LLM use in enterprises is how to combat the hallucination problem. The most prevalent LLM use case is the deployment of knowledge assistants, which is almost invariably coupled with a discussion of retrieval augmented generation (RAG).
Improving the accuracy of LLM output is the central theme of each of these themes. There would be no discussion here if LLMs weren’t so good at their job when they are accurate. But they are very good. So, a key question is how to make them more accurate for all tasks and identify the accuracy threshold for various use cases.
Indeed, inaccurate information is everywhere. It’s on the internet, government websites, company websites, news sites, YouTube, Wikipedia, and just about every other niche of knowledge. You may note that these information sources also present the information as authoritative. Most of the errors are unintentional. However, it still happens, and we should not act as if LLMs are unique in their inaccuracy.
What is novel is that LLMs introduce a seemingly new category of inaccuracy, or one that is very rare among humans: hallucination. In human editorial terms, the root cause of inaccuracy often occurs when typos are not caught, the writer uses inaccurate source information, the interpretation of information is incorrect, or a key fact is misremembered. The source of the inaccuracy is generally easier to identify upon investigation than with LLMs, which connect vector data points in an untraceable sequence.
Since there is little near-term hope of eliminating or even tracing the source of the “hallucinations,” users have focused on techniques to reduce their occurrence. Fine-tuning, RAGs, and prompt engineering are the most popular approaches today. By far, the simplest and least costly of these is prompt engineering.
What it Means
This could be a particularly significant discovery. Fine-tuning is expensive and time-consuming. If domain specialization only requires refined prompt engineering, it could accelerate time-to-market and reduce cost. It also may undermine some of the arguments behind creating custom models. If you can get the same or better performance from a general-purpose foundation model, why would you go to the trouble of creating your own?
Well, it’s not quite that simple. Accuracy is only one of the reasons why companies are looking at creating customized LLMs. As I pointed out in yesterday’s post about NVIDIA’s NeMo framework and tools for customized AI models, data privacy, data and application security, cost, and competitive advantage are also important motivations.
At the same time, we should not read too much into the study. The authors still seem to believe that LLMs have emergent properties based on one of the paper’s citations when there is considerable disagreement on that point and a study that concluded the claim was based on information influenced by test measurement bias. Other points to ponder:
Is the performance of GPT-4 with custom prompting matched by other foundation models, or is there something unique about its design, training, and inference?
Would a fine-tuned version of GPT-4 combined with the specialized prompt techniques provide even better results?
Microsoft’s researchers acknowledged that the combinatorial effects of multiple techniques may deliver even better results.
While our investigation focuses on exploring the power of prompting generalist models, we believe that fine-tuning, and other methods of making parametric updates to foundation models are important research avenues to explore, and may offer synergistic benefits to prompt engineering.
As I mentioned, there are many reasons why an enterprise may decline to use GPT-4, even if it is the best model. However, Medprompt suggests new benchmarking techniques should be used to compare a specialty model’s performance against generalized foundation models.

ChatGPT Turns 1 - Timeline of a Remarkable First Year and its Impact on Industry and Society

Happy Birthday, ChatGPT! It is hard to overstate how much ChatGPT changed the world’s interest in generative AI. I was using InstructGPT in the OpenAI playground to assist with search in early 2022 and had covered the GPT models as an analyst in 2020. My first article on what we now call generative AI was in 2017. In June 2022, Eric Schwartz and I decid…
Galileo's Hallucination Index and Performance Metrics Aim for Better LLM Evaluation

Galileo, a machine learning tools provider that helps companies evaluate and monitor large language models (LLM), has introduced a new LLM Hallucination Index. The Index evaluated 11 leading LLMs to compare the probably of correctness for three common use cases: