

Measuring Foundation Model Transparency
Is Stanford's new AI model transparency index comprehensive or overkill?


Stanford’s Center for Research on Foundation Models (CRFM) and the Institute on Human-Centered Artificial Intelligence (HAI) have introduced a Foundation Model Transparency Index (FMTI). It is a robust (well, too robust) rubric for evaluating foundational model information transparency based on 100 “indicators” segmented into three domains: upstream, model, and downstream. The concept is helpful as competing and ambiguous definitions of foundation model transparency are already circulating.
Regulators are currently considering what metrics to include in government rules for AI foundation models. In theory, a comprehensive rubric for assessing transparency created by industry-focused research institutes could be invaluable in these policy-setting processes. However, a close review of the 100 indicators includes an overly broad view of what constitutes transparency. An unintended consequence of this 100-point framework is that it may be roundly ignored because it is too cumbersome to execute, and many indicators require subjective human assessment to score.
In addition, several of the indicators score items that are not specifically linked to public interest regarding the training, operation, and output of foundation models. The indicators are inclusive of labor practices, partner identification, and hardware ownership, for example. This information would be interesting for some parties to know. For example, I would like to have all of this information myself, and I’m sure the Stanford academic researchers would like to be able to replicate the models. And there may be some public good associated with this information or potentially indirect impact on model composition and function. However, these links are often tenuous to the safety concerns related to foundation models.
The researchers may believe their approach is comprehensive and, therefore, good. An alternative perspective is that the FMTI is comprehensive to the point of impracticality and goes beyond a reasonable set of disclosure requirements. These factors suggest that the FMTI scoring may become a disincentive for companies to provide even modest transparency because they will receive high scores under no practical scenario.
A better approach is to take a subset of the highest impact of the 100 indicators and work with industry and government to encourage adoption.
Do the Results Indicate Value?
Before we consider some of the superfluous indicators, evaluating the usefulness of the initial FMTI results is worthwhile. According to HAI:
Companies in the foundation model space are becoming less transparent, says Rishi Bommasani, Society Lead at the Center for Research on Foundation Models (CRFM), within Stanford HAI. For example, OpenAI, which has the word “open” right in its name, has clearly stated that it will not be transparent about most aspects of its flagship model, GPT-4.
Less transparency makes it harder for other businesses to know if they can safely build applications that rely on commercial foundation models; for academics to rely on commercial foundation models for research; for policymakers to design meaningful policies to rein in this powerful technology; and for consumers to understand model limitations or seek redress for harms caused.
The 100 indicators range from information about data, methods of content filtration, and risk description to model architecture, prohibited use, and user data protection.
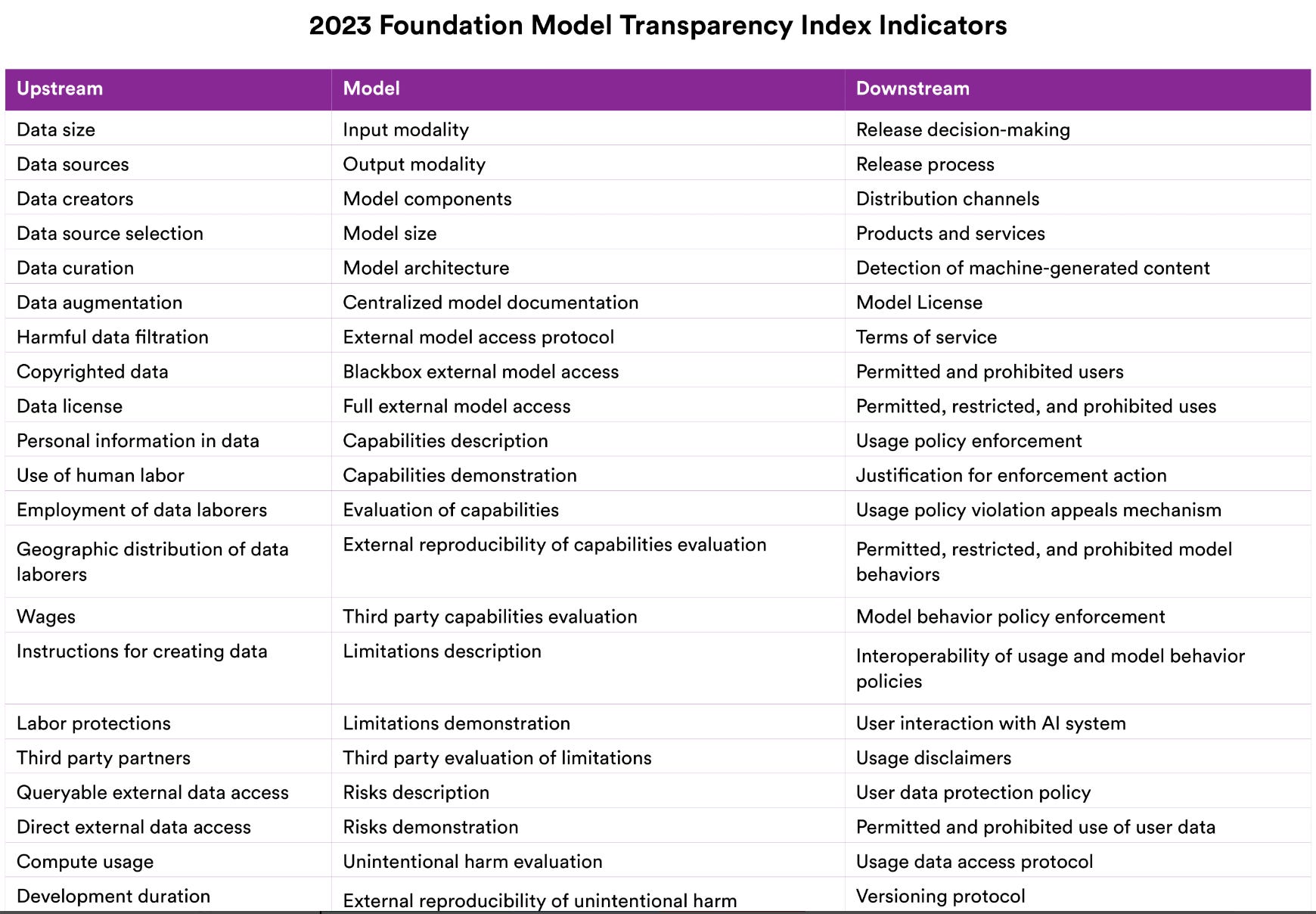
Data size and sources are reasonable transparency measures. Queryable access to data also adds transparency. Reproducibility, model components, model size, and model architecture are also measures that most third parties and regulators will find useful in evaluating foundation models.
A practical set of measures may include these indicators but would be far more limited . The data (upstream), the model, and the outputs (downstream) represent a useful segmentation. The key will be to promote only a few indicators in each domain.
Guaranteeing Transparency Failure
There are multiple reasons why you don’t want to require foundation model developers to follow a 100-point checklist. First, it leads to a false equivalency. Not all of the 100 transparency indicators are equally beneficial in providing, well, transparency. Labor protections and compute usage should not be viewed as comparable to data sources when considering a model transparency rating.
Second, with such a long list and binary scoring for each indicator, you could see foundation model developers looking to score points in areas that are less impactful in providing true transparency. That might enable them to achieve higher scores while providing less actual transparency.
Third, there are indicators that may address a social good but don’t have direct impact on any type of transparency that enable a technical or safety assessment of the model. For example, Data Labor indicator focuses on whether human data labelers are employed in developing the foundation model. Since these are not measurable inputs, it is essentially impossible to ascertain their impact on model performance and therefore transparency doesn’t help a third party better understand the model or its expected output.
Fourth, there are technical indicators that also would not be expected to provide meaningful transparency insight. Whether a model was trained on A100s or H100s, or training was run on AWS, Azure, Google Cloud, or in your basement, it does not tell you much about expected harm associated with outputs. However, it would provide insight for reproducibility. This might be useful for independent third-party audits but it also shares private business information without a compelling reason to provide it in terms of consumer protection.
Fifth, if foundation model providers see the indicator checklist as too cumbersome or impossible to make progress against, they may abandon transparency efforts altogether. The more complex the audit, the less likely the participation.
Sixth, the results of the FMTI evaluation show its shortcomings.
Considering the Data
FMTI indicates that Meta’s Llama 2 is the most transparent, with a score of 54%. It is followed by the open-source BLOOM model at 53%. That is followed by OpenAI’s proprietary GPT-4 at 48%. The researchers claim success because three of the top four models in the FMTI are open-source and that is what you’d predict. However, how do they explain away the presence of a closed and proprietary model (GPT-4) at the top of the interview?
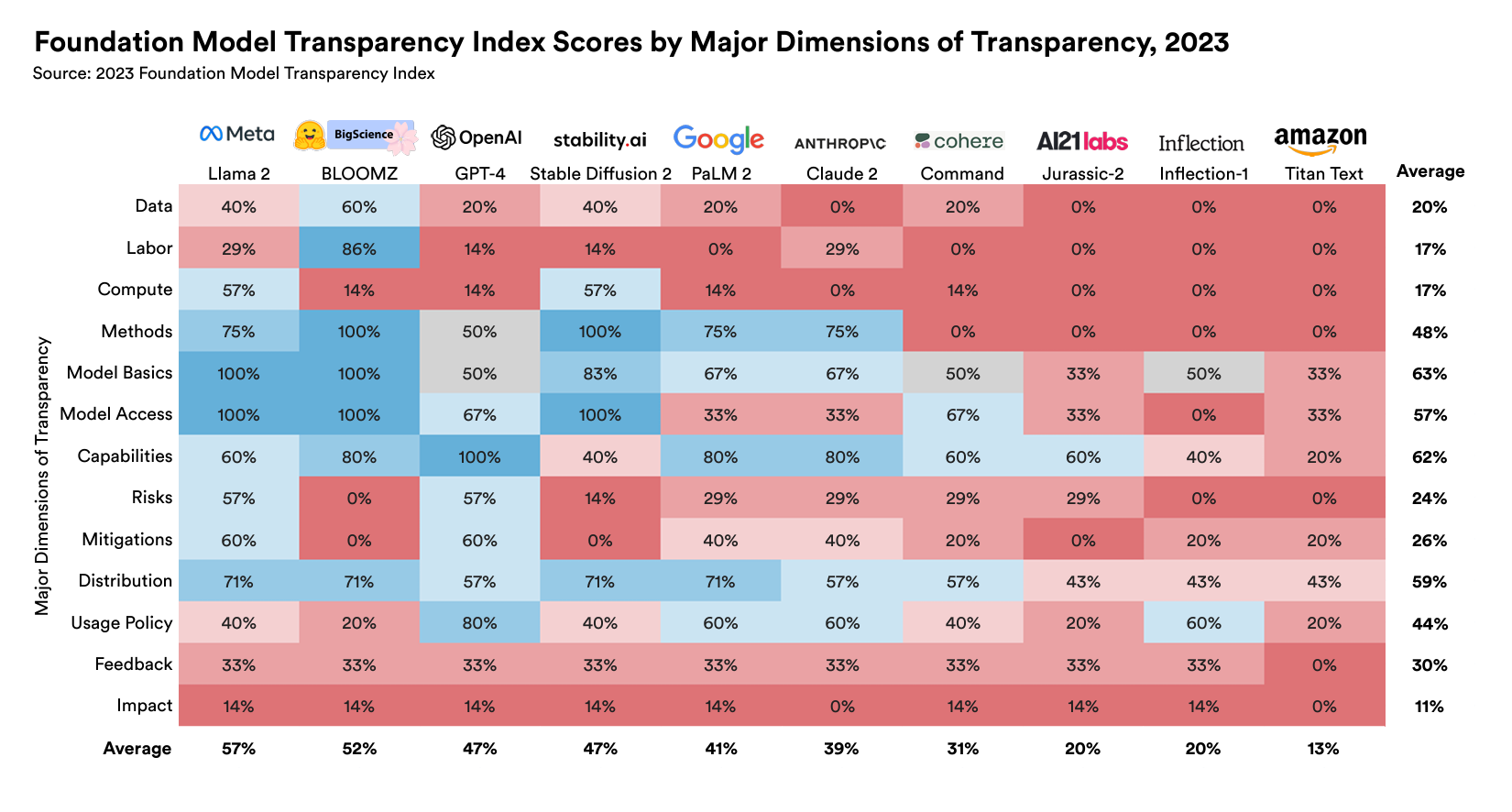
This result is largely because OpenAI, a proprietary model, is so strong Methods, Model Basis, and Model Capabilites, mitigation, and distribution. It is also not what you would expect to see when comparing transparency levels. I suspect the Stanford Institutes are thinking too much about information they would like to know versus data that is essential to externally evaluate or regulate the development of LLMs.
My recommendation is to review FMTI and identify which indicators apply to you and which actually enable you to asses transparency. Then whittle down the list to something more manaeiable. I would not attempt to match all of the indicators, just those that are necessary.
Learn More about LLMs
If you want to learn more about large language models (LLM), join me at the Synthedia 4 online conference focused on LLM Innovation this week. The event is free, but you must register. Azure OpenAI Services, Amazon Bedrock, NVIDIA, Bing Chat, Applause, and others will present.
The Implication of OpenAI's False Start on Arrakis

The Information reported that OpenAI was working on a model upgrade to ChatGPT called Arrakis in late 2022 and early 2023. At the time, ChatGPT was using the new GPT-3.5 model tuned for the chat user experience. OpenAI already planned to upgrade ChatGPT’s performance with the GPT-4. However, a new model, Arrakis was supposed to upgrade ChatGPT again by …