

Meta's Code Llama is the New Open Source Alternative to GitHub Copilot
The code generation market heats up


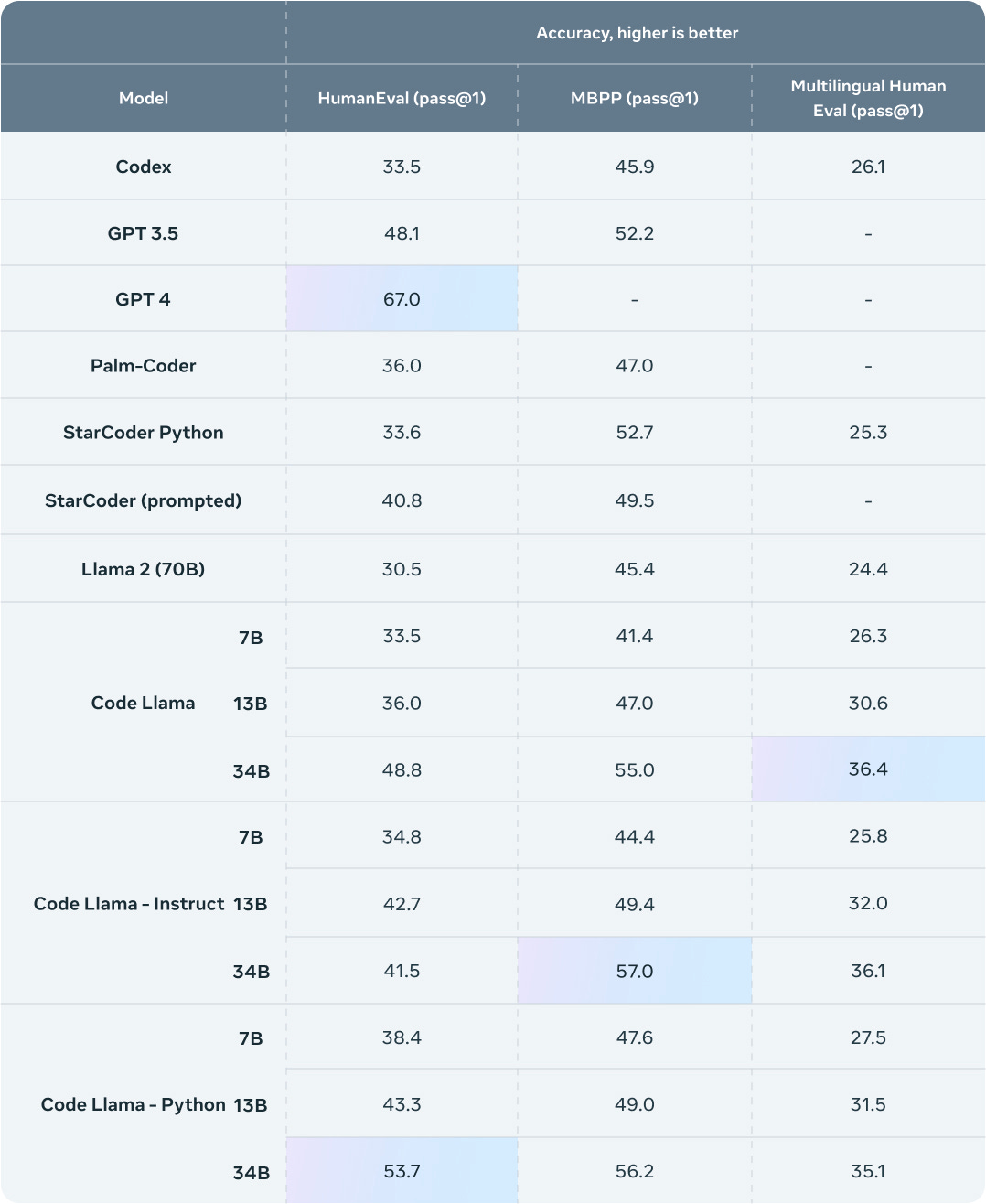
Meta this week announced Code Llama, an open-source code generation solution built on the Llama 2 large language model (LLM). Code Llama is not the first open-source code generation solution. However, it may be the most capable. Meta also released its benchmark for Code Llama and showed its performance across several tests where it bests Hugging Face’s StarCoder, along with Open-AI’s Codex, and GPT-3.5.
Why Open-Source Code Generation Matters
Code generation has become a “killer app” of generative AI. Lead by OpenAI’s Codex and Microsoft extension into GitHub Copilot, a Stack Overflow survey of nearly 90,000 software developers found that 44% are already using generative AI-based coding solutions, and another 25% plan to adopt them soon.
However, some companies are concerned about using proprietary solutions to generate new code or interpret their existing code due to the risk of leakage of their software code base. Samsung banned ChatGPT use by employees earlier this year after one employee purportedly uploaded closely guarded firmware software into OpenAI’s popular generative AI chatbot.
Code Llama provides the opportunity for enterprises to host their own instance of the generative AI code generation solution and ensure their software secrets are never exposed to outside parties.
At Meta, we believe that AI models, but LLMs for coding in particular, benefit most from an open approach, both in terms of innovation and safety.
There may also be cost benefits, particularly for generative code at scale. However, the primary interest today is driven by the ability to have more control over the model and where the data travels.
Multiple Sizes, Models, and Large Context Window
Meta is releasing three different model sizes for each of three code generation models. Code Llama is the general-purpose model, while Code Llama-Instruct and Code Llama-Python offer models fine-tuned for human-prompted code generation tasks, and Python coding, respectively. Each is offered in 7B, 13B, and 34B parameter sizes and was trained on more than 500B tokens.
We are releasing three sizes of Code Llama with 7B, 13B, and 34B parameters respectively. Each of these models is trained with 500B tokens of code and code-related data. The 7B and 13B base and instruct models have also been trained with fill-in-the-middle (FIM) capability, allowing them to insert code into existing code, meaning they can support tasks like code completion right out of the box.
The three models address different serving and latency requirements. The 7B model, for example, can be served on a single GPU. The 34B model returns the best results and allows for better coding assistance, but the smaller 7B and 13B models are faster and more suitable for tasks that require low latency, like real-time code completion.
The Code Llama models provide stable generations with up to 100,000 tokens of context. All models are trained on sequences of 16,000 tokens and show improvements on inputs with up to 100,000 tokens.
Aside from being a prerequisite for generating longer programs, having longer input sequences unlocks exciting new use cases for a code LLM. For example, users can provide the model with more context from their codebase to make the generations more relevant. It also helps in debugging scenarios in larger codebases, where staying on top of all code related to a concrete issue can be challenging for developers. When developers are faced with debugging a large chunk of code they can pass the entire length of the code into the model.
The large context window of up to 100k tokens may be the most surprising feature of Code Llama. GitHub Copilot only has about and 8k context window. That means Code Llama can maintain context of more code and more instructions from the developer, which you should expect to deliver better and more reliable results.
Hugging Face’s announcement of Code Llama’s availability commented on how this was achieved:
Increasing Llama 2’s 4k context window to Code Llama’s 16k (that can extrapolate up to 100k) was possible due to recent developments in RoPE scaling. The community found that Llama’s position embeddings can be interpolated linearly or in the frequency domain, which eases the transition to a larger context window through fine-tuning.
Generative AI Code Battles are Heating Up
Microsoft has established an early lead in the generative AI code generation segment with GitHub Copilot. However, market competition is increasing, and Code Llama, with its apparent strong performance and open-source status, is likely to quickly become a strong contender for developer loyalty and company preference.
The AI Code Generation Battles Heat Up with Google Codey Debut

In early March, a Synthedia post identified 5 product categories already disrupted by generative AI. Topping that list is coding. Almost every software developer I know has tried at least one AI coding assistant. Some agree with the numbers from Github that the tools can reduce job effort by about 50% of the current level of effort for similar or common…
Hugging Face Lands $235 Million in Funding and a Giant New Valuation

Hugging Face announced today that it raised $235 million in new funding from tech giants that include Salesforce, Google, Amazon, NVIDIA, AMD, Intel, Qualcomm, IBM, and others. This latest round brings Hugging Face’s total investment to $395 million, according to