



Mistral Has $415M in New Funding, a Big Valuation, and a New LLM to Challenge GPT-4
Open-source is getting a big boost and Mistral has friends in EU government


Editor’s Note: Updates were added on December 11 based on newly released company information about the models and an API service.
Numerous media outlets report that Mistral has just closed a $415 million funding round at a $2 billion valuation. The company also released its latest large language model (LLM) on Friday by posting a torrent link to an 87GB file. The new LLM is probably the bigger news.
Andreessen Horowitz was a key investor in the round. The Financial Times reported earlier this week that it was expected to contribute more than €200 million in the round. Bloomberg reported earlier that NVIDIA and Salesforce were also expected to participate in the funding round.
Who is Mistral?
Mistral is a generative AI foundation model developer focused on building open-source models. The company debuted with fanfare to its $113 million seed-funding round in June and the Mistral 7B LLM release in September. Microsoft CEO Satya Nadella name-checked Mistral and the new Hugging Face Zephyr 7B model based on Mistral 7B at the company’s annual Ignite Conference. It was also the only generative AI company besides OpenAI mentioned specifically during the press conference announcing the new EU AI Act.
The Paris-based company was founded in early 2023 by former Meta AI researchers Timothée Lacroix and Guillaume Lample and Arthur Mensch, a former Google Deepmind researcher. Mistral has joined Meta’s AI leader, Yann LeCun, as a strong advocate for open-source generative AI models and sought accommodation from EU AI Act negotiators.
Aleph Alpha, a Germany-based LLM developer, announced $500 million in funding in November. Some people like to view one or both of these companies as the OpenAI of Europe. However, Aleph Alpha offers only proprietary LLMs, while Mistral provides open-source models under the Apache 2.0 license. The logical comparison is to OpenAI GPT-3/4 (proprietary) and Meta Llama 2 (open-source). But these are mostly false comparisons that set an unnecessarily high bar for the European companies. They appear to have their own strengths.
Mistral has surprised many, in a positive way, with its model performance and unorthodox model release approach. Two days ago, the company posted a link in its X account to a torrent link that enabled users to download an 87GB file of its new model. There was no press release, no blog post, no GitHub repo (yet), no doc (yet). And there was no heavily edited video—just a link.

Mixtral 8x7B
Initially, there was limited information about the new Mistral LLM, but it appeared to be a Mixture of Experts (MoE) LLM with access to eight specialized seven billion parameter expert models. Mistral clarified this in a December 11th blog post:
Today, the team is proud to release Mixtral 8x7B, a high-quality sparse mixture of experts model (SMoE) with open weights. Licensed under Apache 2.0. Mixtral outperforms Llama 2 70B on most benchmarks with 6x faster inference. It is the strongest open-weight model with a permissive license and the best model overall regarding cost/performance trade-offs. In particular, it matches or outperforms GPT3.5 on most standard benchmarks.
Mixtral has the following capabilities.
It gracefully handles a context of 32k tokens.
It handles English, French, Italian, German and Spanish.
It shows strong performance in code generation.
It can be finetuned into an instruction-following model that achieves a score of 8.3 on MT-Bench.
…
Mixtral is a sparse mixture-of-experts network. It is a decoder-only model where the feedforward block picks from a set of 8 distinct groups of parameters. At every layer, for every token, a router network chooses two of these groups (the “experts”) to process the token and combine their output additively.
This technique increases the number of parameters of a model while controlling cost and latency, as the model only uses a fraction of the total set of parameters per token. Concretely, Mixtral has 45B total parameters but only uses 12B parameters per token. It, therefore, processes input and generates output at the same speed and for the same cost as a 12B model.
The model download files also included some fun ASCII art.

Dmytro Dzhulga said on X he had downloaded the file and deployed the model using 4x40GB cards and was able to get the model to run. He also cautioned users that there is no official model code yet, so it may not be an optimal implementation. However, he was able to get the model to produce output to a couple of questions.
Performance Benchmarks
The new Mixtral model is positioned as an alternative to OpenAI’s GPT-3.5 and Meta’s Llama 2. Mistral emphasizes comparable or better performance with lower overall compute cost and latency. Mistral published scores for six of the seven standard Open LLM Leaderboard benchmarks plus MBPP, an example of programming prowess.
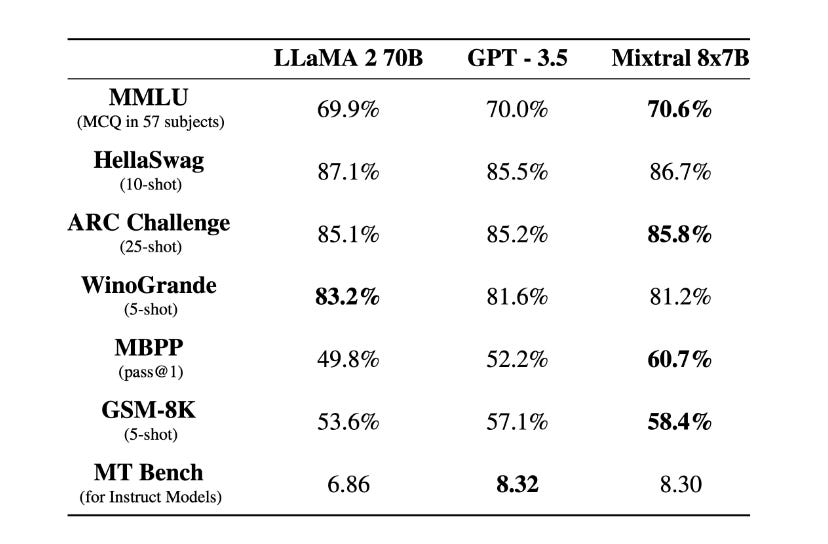

You can see the performance for Mixtral is right in line with Llama 2 70B and GPT-3.5, with Mistral posting the highest score in four of the tests presented. The most notable difference is the MBPP score, where Mixtral 8x7B is materially better. Across a broader set of 12 benchmarks, Mixtral beats all Llama 2 models in nine and is only bested by the 70B model in three.
However, it is worth noting that TruthfulQA is not listed in these results. Hugging Face lists TruthfulQA as “a test to measure a model's propensity to reproduce falsehoods commonly found online.” So, why would an open-source foundation model developer skip one of the six standard benchmarks used for the Open LLM leaderboard?
It is hard to believe TruthfulQA would be omitted from the published results if the performance were comparable to Mistral’s preferred model peers. This suggests additional fine-tuning will be necessary for chat models before being promoted to production.
The key differentiator, however, is not performance. It is efficiency. Mixtral offers more performance per inference cost than Llama 2. So, even where Llama 70B matches or beast Mixtral in the six benchmarks listed below, it requires a significantly higher inference budget.

What it Means
The real promise of this model is that some researchers suggest GPT-4’s breakthroughs were due in large part to its MoE architecture. MoEs enable researchers to run processes in parallel to reduce latency and benefit from multiple fine-tuned models. However, GPT-4 is an LLM where each “expert” sub-model is very large in terms of parameter size. That makes it expensive to run.
Mistral’s first 7B model performed better than rival open-source LLMs and compared favorably to several with tens of billions of parameters. Yet the smaller model size meant it generally would be less costly to operate and have lower latency. The expectation is that Mixtral 8x7B model will deliver another step up in LLM performance using an MoE of smaller models, thus benefitting from better efficiency and better performance in output quality and accuracy. The data Mistral presented reinforces this supposition.
However, this is only part of the story. In a companion blog post on December 11th, Mistral introduced La Platforme, which “serves three chat endpoints for generating text following textual instructions and an embedding endpoint. Each endpoint has a different performance/price tradeoff.” Mistral 7B is listed as Tiny, Mixtal 8x7B is Small, and another model called Mistral Medium is larger and delivers even higher performance.

This is generating enthusiasm that scaling MoE models can start to match GPT-4 performance and do so with lower latency and cost. That would be a very important development.
The open-source LLM market is getting more interesting, and it looks like three Ms are leading the pack: Meta, MPT, and Mistral. Now we get to see if another M, MoE, helps open-source LLMs become a true rival to GPT-4. Granted, Redpajama and Yi might suggest some alphabetic diversity in that list.

Aleph Alpha Lands $500M, Contends for "OpenAI of Europe" Status

Aleph Alpha, the Germany-based large language model (LLM) developer, has announced a $500 million funding round that included strategic investors Ipai, Bosch, HP, and SAP, among others. The company had previously raised over $140 million in earlier funding rounds. According to the
Google's Gemini LLM Arrives Next Week and It May Just Outperform GPT-4 (sort of)

Google CEO Sundar Pichai announced in a blog post that the Gemini large language model (LLM) will launch next week as an API in Google AI Studio and Vertex AI in Google Cloud. The solution is regarded as a replacement for the company’s current flagship LLM, PaLM. This represents the third LLM product family that Google has used this year, including the …