OpenAI Shows How it Will Improve ChatGPT's Reasoning Skills in New Paper
Process success can lead to outcome success


OpenAI has released a new research paper exploring the benefits of large language model training (LLM) based on process supervision. Typical reinforcement learning with human feedback (RLHF) focuses on outcome supervision. The outcome-oriented evaluation considers whether the response of the large language model (LLM) is correct and appropriate. There is no consideration of the steps taken to reach the result.
The result is that the feedback mechanism used for model training cannot help to surface where errors arise that lead to poor results. This is particularly problematic for math and other complex reasoning problems.
Process Supervision for Model Training
By contrast, a process-oriented evaluation (i.e., supervision) considers the quality of intermediate step performance and how they help impact LLM response quality. A post by OpenAI about the new report states:
In recent years, large language models have greatly improved in their ability to perform complex multi-step reasoning. However, even state-of-the-art models still produce logical mistakes, often called hallucinations. Mitigating hallucinations is a critical step towards building aligned AGI.
We can train reward models to detect hallucinations using either outcome supervision, which provides feedback based on a final result, or process supervision, which provides feedback for each individual step in a chain-of-thought. Building on previous work, we conduct a detailed comparison of these two methods using the MATH dataset as our testbed. We find that process supervision leads to significantly better performance, even when judged by outcomes.
The research paper adds:
Outcome-supervised reward models (ORMs) are trained using only the final result of the model’s chain-of-thought, while process-supervised reward models (PRMs) receive feedback for each step in the chain-of thought. There are compelling reasons to favor process supervision. It provides more precise feedback, since it specifies the exact location of any errors that occur.
It also has several advantages relevant to AI alignment: it is easier for humans to interpret, and it more directly rewards models for following a human-endorsed chain-of-thought. Within the domain of logical reasoning, models trained with outcome supervision regularly use incorrect reasoning to reach the correct final answer (Zelikmanetal., 2022; Creswelletal., 2022). Process supervision has been shown to mitigate this misaligned behavior(Uesatoetal.,2022).
Reward Models
If you are unfamiliar with reward models, think of the AI model as a student that responds favorably to positive feedback—the reward. When a model receives positive feedback, it will typically repeat that behavior in the future for a similar prompt request to again receive the reward.
Similarly, negative feedback teaches the model what to avoid in the future and to seek alternative responses that will be more likely to receive a reward. This becomes important in multi-step reasoning processes. If several steps are involved in producing a response, and the model receives negative feedback, it does not know what step should be avoided in the future.
The PRM model offers feedback on which steps were rewarded and which were not. Future prompt requests can then be answered by selecting the known good (i.e., rewarded) reasoning steps and working to improve on the unrewarded steps.
This is much closer to the way humans learn complex skills. Very often, you must master the component steps in order to master the overall task.
Results and the Alignment Tax
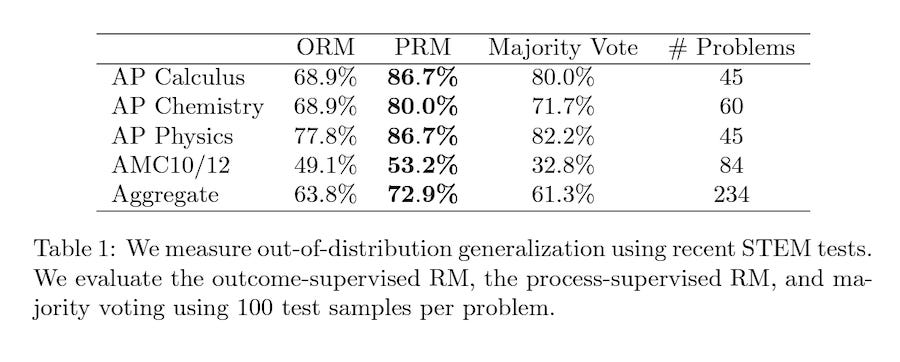
You can see that OpenAI’s results for process reward models (i.e., process supervision) significantly outperform the outcome reward models (i.e., outcome supervision). The chart at the top of the post also shows how the performance gap widens as more training samples are added. While it requires a different training approach that is likely more labor-intensive for RLHF processes, the benefits could be significant.
And there is another interesting discussion and potential benefit about the impact of what researchers call the alignment tax.
Process supervision has several advantages over outcome supervision related to AI alignment. Process supervision is more likely to produce interpretable reasoning, since it encourages models to follow a process endorsed by humans. Process supervision is also inherently safer: it directly rewards an aligned chain-of-thought rather than relying on outcomes as a proxy for aligned behavior (Stuhlmüller and Byun, 2022). In contrast, outcome supervision is harder to scrutinize, and the preferences conveyed are less precise. In the worst case, the use of outcomes as an imperfect proxy could lead to models that become misaligned after learning to exploit the reward signal(Uesatoetal…, 2022; Cotra, 2022; Everittetal…, 2017).
In some cases, safer methods for AI systems can lead to reduced performance (Ouyangetal…, 2022; Askelletal…, 2021), a cost which is known as an alignment tax. In general, any alignment tax may hinder the adoption of alignment methods, due to pressure to deploy the most capable model. Our results show that process supervision in fact incurs a negative alignment tax. This could lead to increased adoption of process supervision, which we believe would have positive alignment side-effects. It is unknown how broadly these results will generalize beyond the domain of math, and we consider it important for future work to explore the impact of process supervision in other domains.
The key point here is that alignment objectives, whether focused on safety, truthfulness, or other factors, introduce an additional reward mechanism beyond performance. That can lead to lower model performance in outcome quality and accuracy as the model tries to balance seeking success across multiple reward signals. Alignment typically leads to trade-offs.
Interestingly, the researchers observed that the PRM in process supervision led to a “negative tax,” which meant alignment and outcome quality rose using this approach. It may not always be true, but improved performance alignment coupled with better performance is an important finding because we could have seen the opposite effect.
Why This Matters
Generative AI models today offer a mix of pedestrian and astonishing features. However, complex reasoning skills are a known deficiency. LLMs also lack what we call common sense. Better reasoning can help shore up the most obvious shortcoming of LLM performance. Copilots with advanced reasoning skills and common sense will be even more valuable than what we use today.
ChatGPT App Analysis - 500k Downloads, 45 Countries, and Taking on GPT-Powered Apps

TLDR; ChatGPT’s iOS app is not in more than 40 countries The app is #1 in productivity in the U.S. apps store Data show that it is the second most successful app since January 2022 in terms of first 5-day downloads 11 of the top 40 productivity apps in the App Store are generative AI chat apps and at least nine of them are using OpenAI GPT models