

OpenAI Wants You to Use GPT-4 to Moderate Your GPT-4 Based Application
What it is. What it is not. And what it could be.

OpenAI is promoting the use of GPT-4 for content moderation. You can be forgiven for assuming this product is for social media platforms and online games. It may be a good option to automate some moderation activities on those platforms, but the company is looking at a different risk of large language model (LLM) backed solutions. You don’t control the inputs.
OpenAI recommends an approach employing GPT-4 to monitor and moderate the prompt inputs to large language models (LLM). According to the blog post:
Content moderation demands meticulous effort, sensitivity, a profound understanding of context, as well as quick adaptation to new use cases, making it both time consuming and challenging. Traditionally, the burden of this task has fallen on human moderators sifting through large amounts of content to filter out toxic and harmful material, supported by smaller vertical-specific machine learning models. The process is inherently slow and can lead to mental stress on human moderators.
We're exploring the use of LLMs to address these challenges. Our large language models like GPT-4 can understand and generate natural language, making them applicable to content moderation. The models can make moderation judgments based on policy guidelines provided to them.
Based on the first 30 seconds of the video, you may think this is about moderating model outputs. The graph related to training moderation teams would seem more aligned with that use case. However, all of the examples from the video and the process diagram below are related to classifying model inputs. So, let’s first look at the process related to model inputs and then discuss the applicability to output review requirements.
How it Works
If you watched the video above, you already know this is not a plug-and-play solution. There are several steps involved. OpenAI provided the diagram below to show how the process works, and Synthedia overlayed the numbers so you can get a better sense of the work involved.
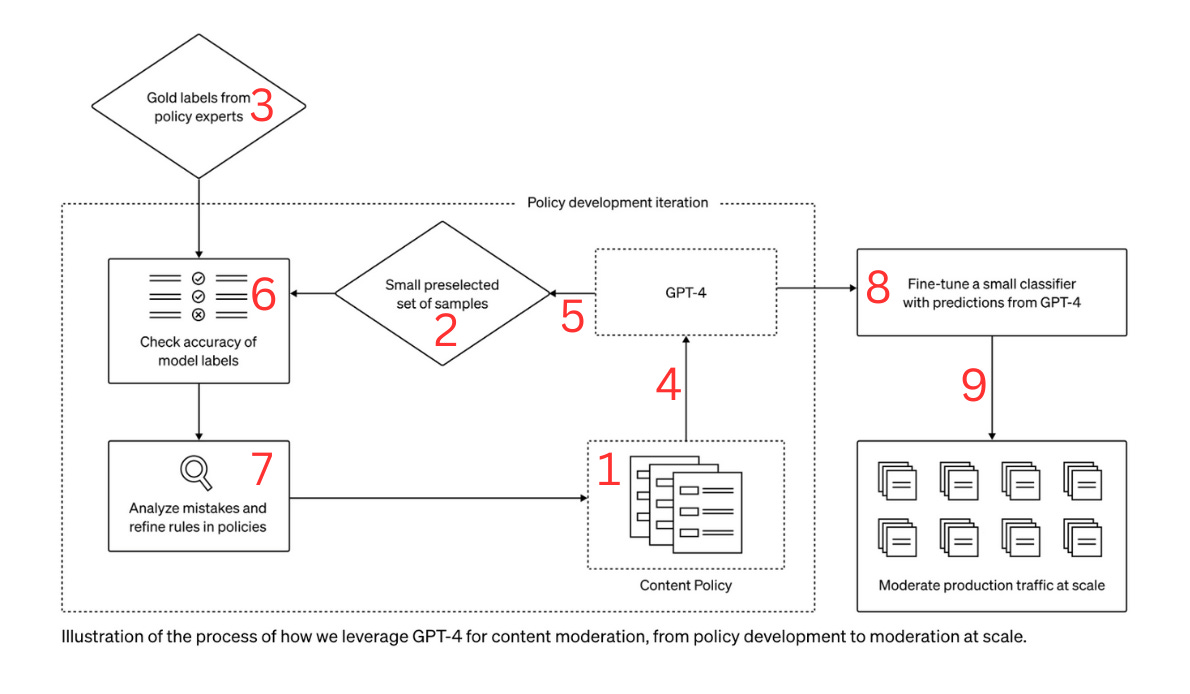
Create a content policy - The policy defines topics, concepts, and words that you do not want to be presented in system inputs. When these are identified in a prompt, the system should know not to answer the question or execute the task.
Create training examples - The training examples should be a mix of acceptable and unacceptable prompts based on the policy that you can use to evaluate the GPT-4 moderator performance and improvement through training cycles.
Create an answer key - The “Gold Labels” are the human expert reviews of whether a prompt training example is acceptable based on the policy.
Ingest the policy into GPT-4 - Upload the policy into GPT-4 so it has instructions on how to evaluate the training examples.
Use GPT-4 to classify the examples - GPT-4 is then used to review each training example and determine if it is permissible based on the policy.
Evaluate the results - Compare GPT-4’s classification with the “Gold Labels” answer key.
Refine policy - Use the results from step 6 to refine the policy definitions and instructions for GPT-4. Run steps 4, 5, 6, and 7 until the system meets the required performance criteria.
Create a smaller fine-tuned model (optional) - You could use GPT-4 at inference, but OpenAI recognizes this might not be cost-effective at scale (or latency acceptable at scale 😀). So, they recommend fine-tuning a smaller model based on GPT-4’s prediction data.
Automate moderation at runtime - You then use the smaller fine-tuned model to moderate prompt inputs in production.
Beyond the content policy written for humans, you will also need to consider how to instruct GPT-4 to utilize the policy in grading the training examples. This will be refined along with the policy during the iterative training process.
In addition, the idea here is that each user-entered prompt will be reviewed by the “Small Classifier” model before being passed along to the large language model (LLM) to generate a response. There is no need to conduct inference on a prompt that violates moderation policy. That would only generate unnecessary inference cost. The cost of running the “Small Classifier” will be far less than GPT-4 and other top-performing models, so it is another cost savings technique.
What This is Not and What it Could Be
It may be clear that this suggested use case is not about evaluating model outputs. The moderation example is about ensuring that the user prompts don’t violate policy.
This means there is no hallucination or truthfulness detection using this approach. Nor is there an evaluation of whether the generated output follows the content policy. However, this same approach could be used in the latter use case.
If there is a concern beyond truthfulness for LLM-generated output, the same “Small Classifier” or another specialized model could review the output for policy compliance before printing it to the screen. Some LLM-based chat solutions are already using a similar approach.
There is a user experience trade-off regarding when you conduct that policy compliance review at runtime. If you wait until the entire response is generated before displaying any of it on the screen, you can more accurately detect unacceptable responses and ensure they are not seen by the user in part or in their entirety. However, that will typically increase response latency which is not great for user experience.
You may have noticed that some generative AI chat applications “print” or display the words in the response in real time as they are returned from the LLM. That provides the user with more immediate feedback (i.e., gratification), so they don’t feel like they are waiting as long for their answer. If those chat applications using this streaming approach detect a policy violation, the existing text may be removed from the screen, followed by a new request may be sent to the LLM or an error shown to the user.
For batch processing approaches, there is no need to remove the text from the screen since they don’t display anything that violates policy. The downside is that users typically have to wait longer to see the first text appear on the screen.
You could also see how this output moderation technique could be applied to social media, gaming, and other sources of user-generated content (UGC). I suspect you will find that a fine-tuned LLM will be superior to the algorithmic screening approach used today. With that said, it is unclear whether companies that host UGC would want to take on the extra cost of LLM inference given their scale of operations. The business case would have to rely on reducing the number of human moderators required to review the content.
Monitoring the Input
Many discussions around LLMs focus on hallucinations and the risk of producing untrue responses. Other discussions have centered on the potential for inappropriate responses that reflect bias or violate policy around content generation. Conversations about monitoring user inputs to LLMs are less common. You should expect that to change.
User inputs can be unacceptable based on the content moderation policy. However, they can also be violations related to security. The unacceptable inputs related to topics and security are the type of lower-level solution requirements that almost no one is talking about. They are also the type of requirements that can prevent an otherwise useful system from getting launch approval. Many companies may soon see input violations as more troublesome than hallucinations.
Addressing Adoption Barriers
This push by OpenAI around content moderation may be the result of more customers getting ready to promote solutions to production. Content moderation using GPT-4 is not a new product, but rather an approach to solve a problem using OpenAI’s existing solutions. That is a change from OpenAI’s typical practice of introducing products and leaving it to customers to handle the details.
I suspect we are going to see more of this from OpenAI. The company wants customers to use its models in production solutions, and any best practices it can promote to reduce adoption friction may help accelerate that transition. Of course, it is even better that the solution to the problem is to use another OpenAI product. 💰
What is GPTBot and Why You Want OpenAI's New Web Crawler to Index Your Content

OpenAI has quietly added documentation to its website about GPTBot. According to OpenAI, “GPTBot is OpenAI’s web crawler and can be identified by the following user agent and string.” User agent token: GPTBot Full user-agent string: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.0; +https://openai.com/gptbot)
The New $100M Anthropic Deal with SK Telecom Provides Insight into Where LLMs are Headed

SK Telecom announced a new $100 million investment in Anthropic along with a wide-ranging partnership to develop large language models (LLM) customized to the needs of the telecom industry. The new announcement suggests SK Telecom also participated in the May series C funding round, which totaled $450 million. A translation of the original news release …