

Stable Video Diffusion Likely to Kick Off a Wave of Text-to-Video Services
The solution is still immature, but the tech giants should take notice

Last week, Stability AI released the code and model weights for its latest product, Stable Video Diffusion. This text-to-video model is not the first we have seen, but it may be the first that enables the type of control, innovation, and ease of deployment that Stable Diffusion brought to the AI image generation category.
It is important to note that this model is being presented more as proof-of-concept than a mature solution. The videos are less than four seconds, will not render text properly, may distort faces and other human features, and lack photorealism. That is a key reason that the release is designated for researchers and not the general public.
You might liken this to earlier text-to-video demonstrations from Meta, Google, and NVIDIA. The quality looks similar. The tech giants have probably advanced their model quality and capabilities over the past year but have kept the technology to themselves. Stability AI has just dropped a bomb on the market segment that will put pressure on the tech giants and application providers. Their lead may soon evaporate.
While Stability AI has positioned Stable Video Diffusion for researchers, it also published the code and model weights for anyone to use. That means the Stable Diffusion developer community can start fine-tuning the model and wrapping it with applications. It will also provide significant user feedback that Stability AI can consider as it develops the next version of the foundation model.
This is likely to impact everyone touching generative video, from the foundation models to the applications. The key question is whether the Stable Diffusion effect we saw for text-to-image generation is about to arrive for text-to-video.
Text-to-Video Model Comparison
The new product offers two models, and both are exclusively for short-form video. SVD is capable of producing 14 frames, and SVD-XT can produce 25. Stability AI says that the videos can be rendered as 3 to 30 frames per second and were preferred by human evaluators.
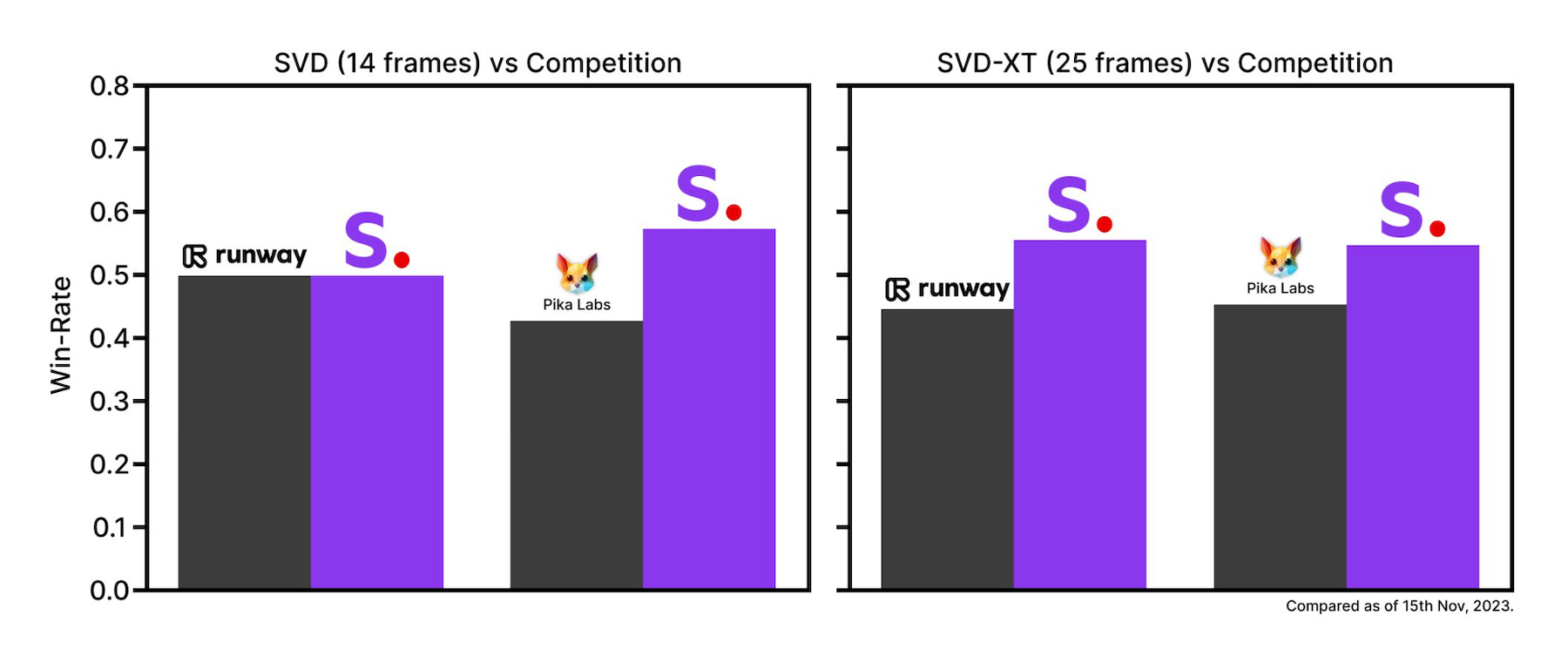
The data show that SVD outperformed Pika Labs and was even with Runway’s Gen-2 model among rater comparisons. SVD-XT surpassed both competing models with a win rate of about 55% to 45% for the other models. The company did not explain why SVD-XT appears to perform less well against Pika Labs than the SVD version. Nor did Stability AI say how many raters were used to evaluate the results, but it did confirm that each image received at least three votes in two categories: visual quality and prompt following.
Creating a Video Diffusion
Stability AI engineers employed a three-stage training methodology to create Stable Video Diffusion:
Stage I: image pre-training, using a 2D text-to-image diffusion model
Stage II: video retraining, training on large amounts of videos with 600 million samples
Stage III: video fine-tuning, which refines the model on a small subset of high-quality videos at higher resolution
An interesting finding was the importance of editing the video samples to account for cuts, fades, and other anomalies that did not align with the video description information. While its original video data training set averages about 2.65 clips per video, after processing for cuts and extraneous imagery, the average climbed to 11.09 clips per video. Researchers were able to show this had a positive effect on output quality.
We are seeing a recurring theme across generative AI foundation model training. While many advances were made and continue to be made based on larger training datasets, better dataset curation is likely to become the next step in driving higher quality.
Bring on the Memes
The biggest impact of Stable Video Diffusion is likely to be how it spreads through the existing Stable Diffusion developer and user bases and to Stability AI’s customers. The company boasts 300,000 creators and developers using its hosted platform and over 10 million using the open-source Stable Diffusion model through all channels and hosts.
Short-form videos have already proven popular. Runway quickly notched a $1.5 billion valuation. Although we noted that Runway’s valuation may have stagnated and its experience suggests there are more difficult growth and monetization challenges than for text generation services, it is still a large market. Stable Video Diffusion may create the impetus for more applications to add the capability and catalyze market growth.
Video has become the lingua franca of our social media age. The ability to create a video to express any thought simply by typing a text description should have a large active base of interested users. This is a logical extension for any service already using a Stable Diffusion model for image generation. Stable Video Diffusion may be extremely immature compared to text-to-image models. However, we saw how fast those models improved in 2022 when finally released into the wild of everyday use.
This release may also bring Stability AI back into a more positive light. Staff conflicts and difficulty raising new funding were not offset by the company’s excursion into large language models (LLM) with Stability LM. That adventure was merely a fine-tuning of a Meta Llama model and did not add a significant contribution to the industry in the same way as Stable Diffusion did for image generation.
Stable Video Diffusion represents a return to Stability AI’s visual roots and will more effectively build on its current business and ecosystem.
What Text-to-Video Is and Is Not
It may be worth noting that some intentional confusion has been generated around the definition of the text-to-video category. Many of the virtual human companies that provide humanlike avatars speaking pre-determined “text” scripts began calling their solutions text-to-video. This was designed to help the companies appear to be more closely aligned with the rising interest in generative AI.
The marketing exercise was not entirely far-fetched. The user enters text, and the software generates a video with an avatar speaking that text. This is a useful product category with text and video involved. However, it is not what we typically think of as text-to-X generative AI solutions, which are open-ended creation engines. The virtual human solutions are more accurately described as script-to-video solutions.
When you use Stable Diffusion, DALL-E, or MidJourney text-to-image solutions, simply enter text describing the image you want to be rendered. Runway, Make-a-Video, Phenaki, Stable Video Diffusion, and other text-to-video solutions work similarly. Script-to-video solutions are a different capability for a different use case. For a pure-play text-to-video solution, there is no script. Another way to think about this is that script-to-video is an application layer solution, while text-to-video is a capability layer solution that can be infused in a wide variety of applications.
It may be that some virtual human companies will expand their offerings to become more video-generation capability-focused, but I doubt that will happen. It may also be true that these companies have used the text-to-video term so widely that there will be confusion about the term, and we will need to assign another to the creation engines, such as Stable Video Diffusion.

You can learn more about Dabble Lab here.
Stability AI: Challenges and Outlook for the One-Time King of Text-to-Image Generation

Editor's note: Bloomberg now reports that Stability AI has explored selling the company, and investors are urging CEO Emad Mostaque to resign. This aligns with Synthedia’s forecast that Stability AI will likely need a white knight acquirer or large investor to survive.
Galileo's Hallucination Index and Performance Metrics Aim for Better LLM Evaluation

Galileo, a machine learning tools provider that helps companies evaluate and monitor large language models (LLM), has introduced a new LLM Hallucination Index. The Index evaluated 11 leading LLMs to compare the probably of correctness for three common use cases: