



Anthropic Says it Just Dethroned GPT-4 from Atop the Frontier Generative AI Model Rankings
Better benchmark results, function calling, big context windows, and code generation

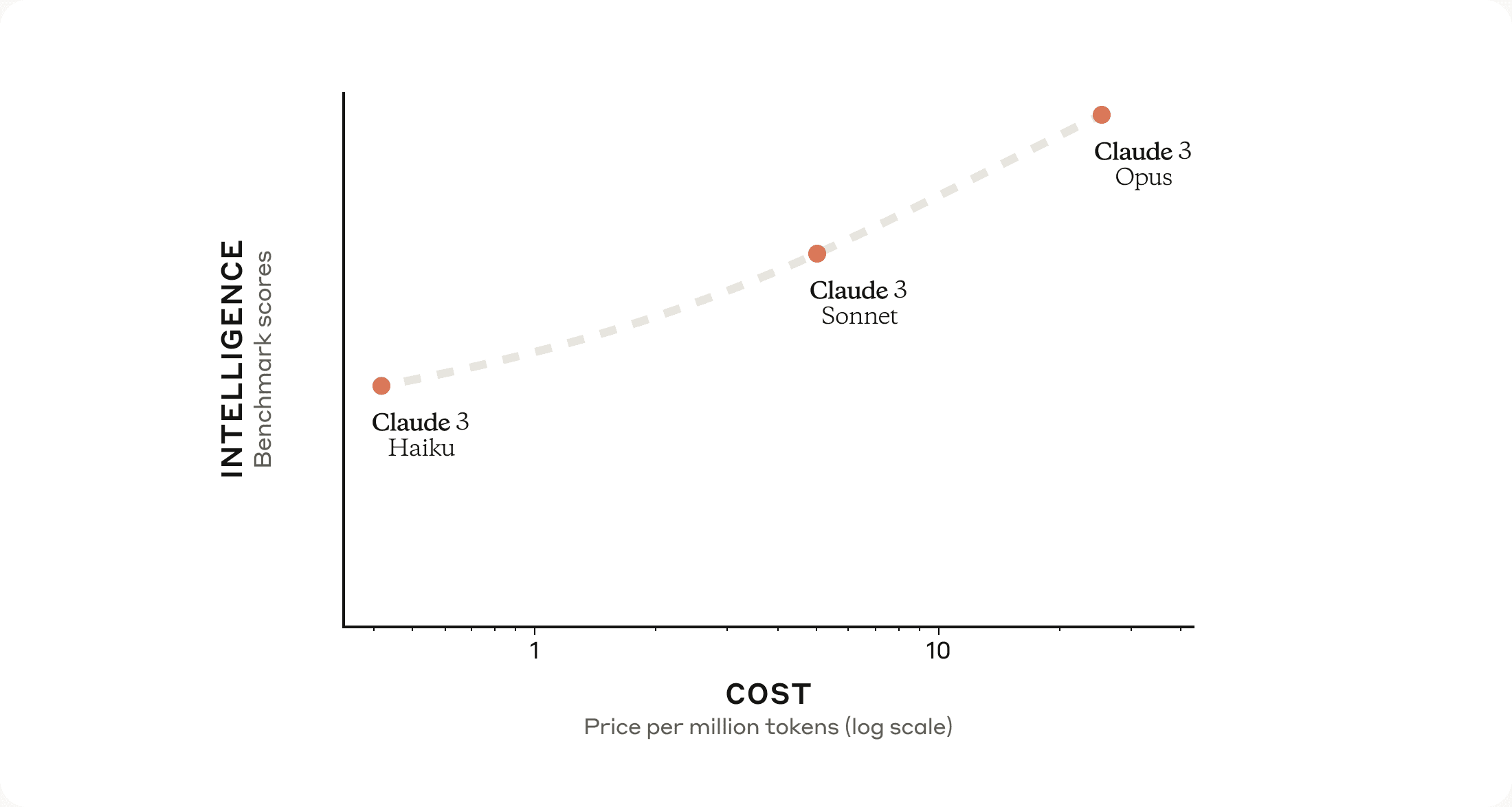
Anthropic’s Claude 3 model family launched today, along with data suggesting it is the first large language model (LLM) with superior performance to OpenAI’s GPT-4 across ten public AI model benchmarks. The product introduction includes the Opus, Sonnet, and Haiku models in descending order of performance and cost. Presumably, this also represents model parameter sizes in descending order.
Opus and Sonnet are available to use today in our API, which is now generally available, enabling developers to sign up and start using these models immediately. Haiku will be available soon. Sonnet is powering the free experience on claude.ai, with Opus available for Claude Pro subscribers.
Sonnet is also available today through Amazon Bedrock and in private preview on Google Cloud’s Vertex AI Model Garden—with Opus and Haiku coming soon to both.
…
We do not believe that model intelligence is anywhere near its limits, and we plan to release frequent updates to the Claude 3 model family over the next few months. We're also excited to release a series of features to enhance our models' capabilities, particularly for enterprise use cases and large-scale deployments. These new features will include Tool Use (aka function calling), interactive coding (aka REPL), and more advanced agentic capabilities.
Each of the Claude 3 models comes with a standard 200K token context window. The company also said the models can support larger context windows, rivaling Google Gemini 1.5, but is not making these capabilities generally available.
All three models are capable of accepting inputs exceeding 1 million tokens and we may make this available to select customers who need enhanced processing power.
In addition, Athropic pointed out several areas of weakness in its earlier model versions, such as Claude 2, and how the updates provide improvements. The most notable of these were fewer rejections of benign questions that the model mistook for AI safety violations and better recall of data in large datasets.
Performance Leadership
Claude 3 represents a significant advance over the 2.1 model release from November 2023. It is also the second recent product introduction that claims superior performance compared with OpenAI’s GPT-4. The first was Google’s Gemini Ultra model, which claimed superiority over GPT-4 across a handful of public benchmarks, though not all. If Anthropic’s data is correct, Claude 3 is highly significant given that GPT-4 has been viewed as a clear performance leader among large language models (LLM) since its launch in March 2023.
Anthropic’s published data suggests it outperforms GPT-4 across the MMLU, GPQA, GSM8K, MATH, MGSM, HumanEval, Drop, Big-Bench-Hard, ARC-Challenge, and Hellaswag benchmarks. These tests represent a broad cross-section of knowledge ranging from facts and math to reasoning and code generation. While many earlier models were released citing results from just a few benchmarks, Google and Anthropic are releasing with benchmarks in the double digits. This reduces the risk of people assuming they are cherry-picking results.

There are many more benchmarks to consider, but most of them overlap, so once you double up or triple up in a few categories, the coverage is generally considered to be sufficient. Common benchmarks that are missing from Anthropic’s announcement are Winogrande for commonsense reasoning, Chatbots Arena for conversational skill in knowledge exchanges with users. We will likely see Anthropic’s numbers either confirmed or invalidated fairly soon through independent analysis of the models. However, it is fair to say GPT-4 has a clear competitor in terms of generalized performance.
In addition, Anthropic released data on five vision capabilities assessment benchmarks where its models consistently outscored OpenAI’s GPT-4V. You will note that Gemini Ultra 1.0 outperforms the Claude 3 Opus model in two of the five benchmarks, ties for one, while the Sonnet and Haiku models each claim one top spot.
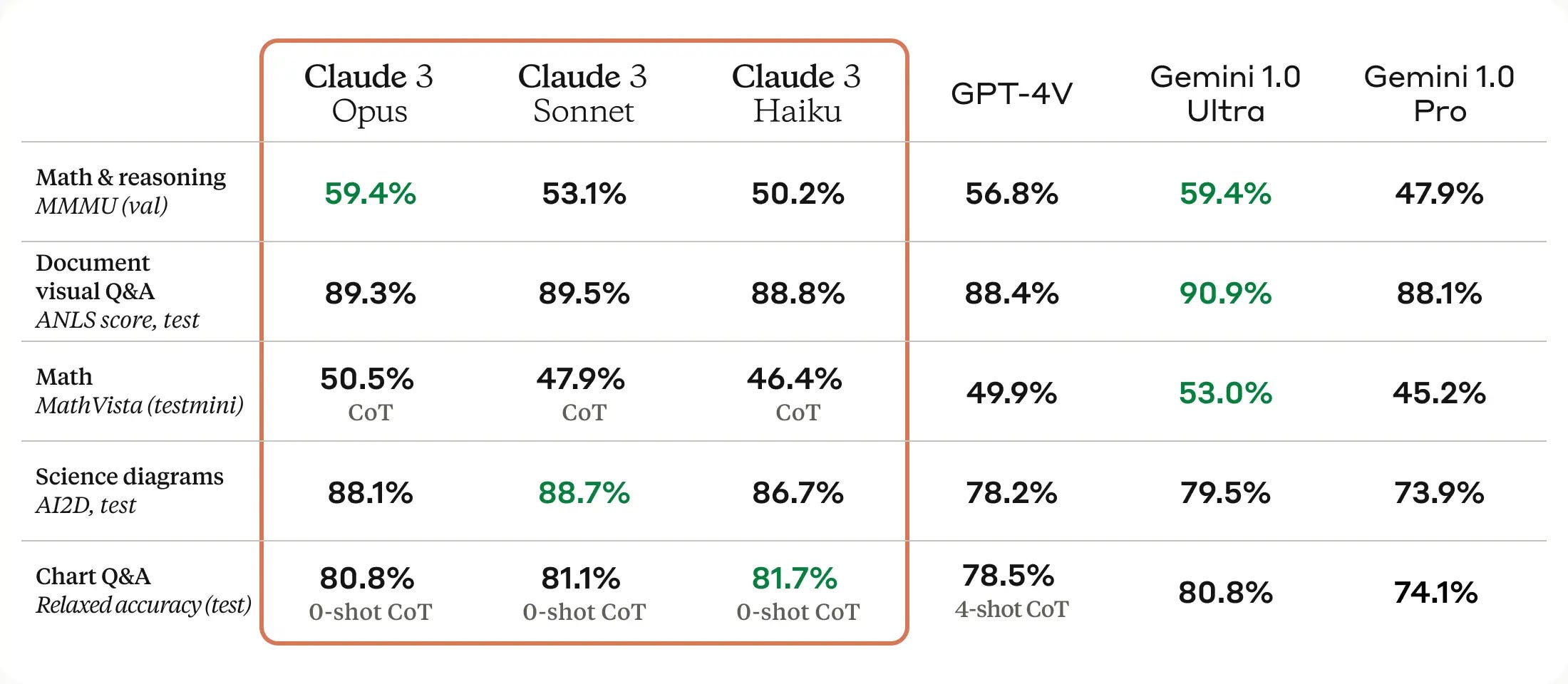
The willingness of Anthropic to publish Claude 3 benchmark data that shows it underperforming slightly compared to Gemini Ultra in some benchmarks would seem to increase confidence that the other data presented is trustworthy.
The GPT Alternative
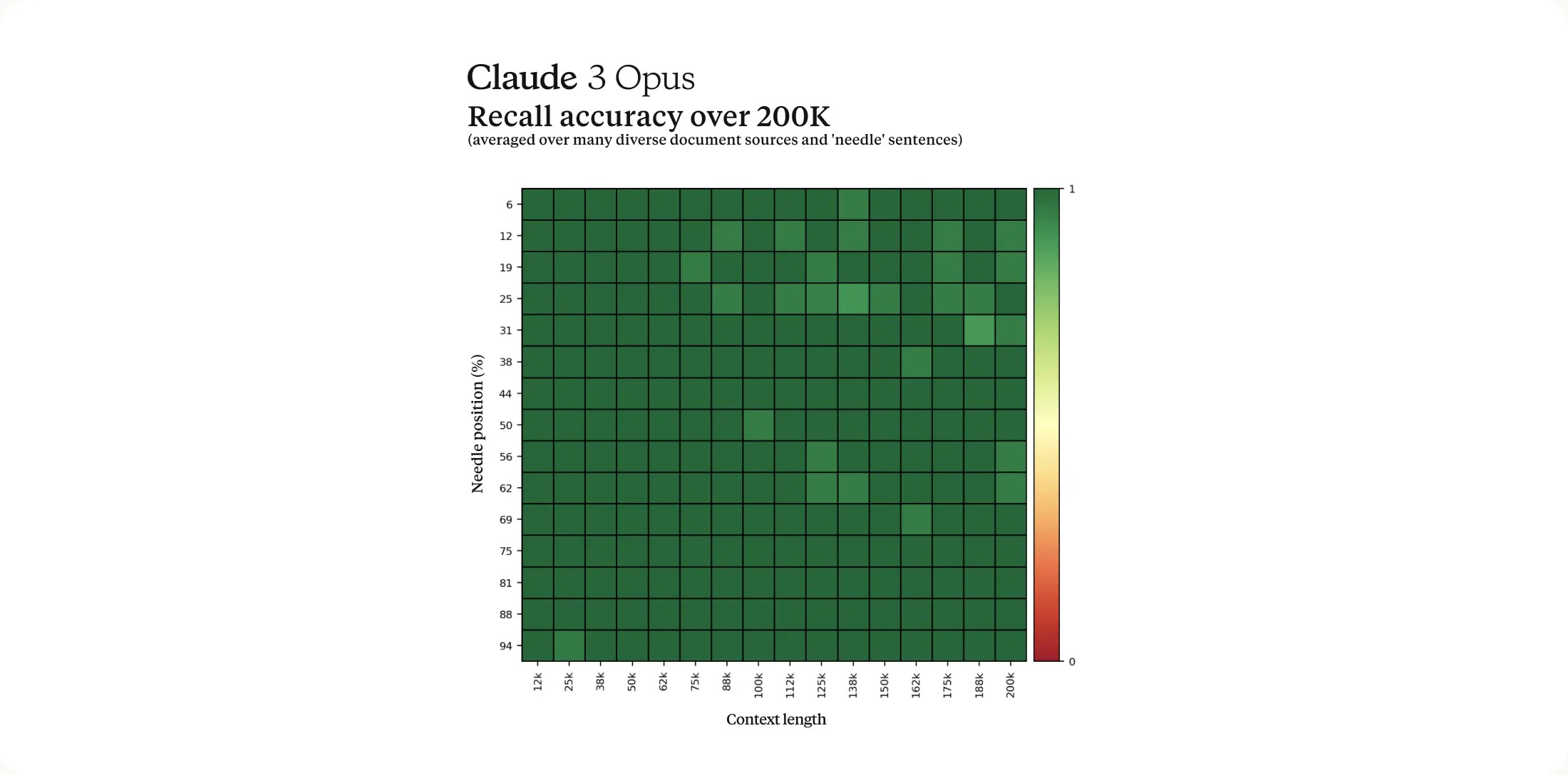
Anthropic’s models have always been impressive in some regards, while including annoying deficiencies in other areas. For example, the large context windows were accompanied by low recall rates for data in the middle third of a token dataset. It also had a high rejection rate for many queries because of its sometimes overzealous AI safety guardrails. The former problem seems to have largely been addressed in the latest release:
To process long context prompts effectively, models require robust recall capabilities. The 'Needle In A Haystack' (NIAH) evaluation measures a model's ability to accurately recall information from a vast corpus of data. We enhanced the robustness of this benchmark by using one of 30 random needle/question pairs per prompt and testing on a diverse crowdsourced corpus of documents. Claude 3 Opus not only achieved near-perfect recall, surpassing 99% accuracy, but in some cases, it even identified the limitations of the evaluation itself by recognizing that the "needle" sentence appeared to be artificially inserted into the original text by a human.
The problem of overly aggressive AI safety guardrails appears to have improved but remains unacceptably high at over 10% for the Opus and Sonnet models. More work needs to be done in that regard.
Function calling was also a notable gap that made Anthropic’s models less versatile for many enterprise use cases. The addition of enhanced coding capabilities will also be welcome, as will the three model sizes that account for lower latency and cost requirements for many use cases.
Anthropic can now rightfully claim to be a rival to GPT-4 on equal terms, and it is closing the feature gap with OpenAI’s model family. However, the more important development is that Anthropic has shown a robust set of improvements just as Google is starting to become more competitive. Both companies are first and foremost competing to become the OpenAI alternative, as it is the clear market share and mindshare leader. Establishing the first alternate position will be a key step in eroding OpenAI’s grip on the market. Gemini’s rise created a risk that Anthropic would be surpassed as the key alternative.
The other winner here is Amazon Bedrock. Azure is winning many enterprise generative AI deals today because it is the only public cloud option for accessing OpenAI’s foundation models. When OpenAI had the two most performant models in GPT-3.5 and GPT-4, the other cloud ecosystems were at a competitive disadvantage. Now AWS has a true GPT-4 rival in Claude 3, while Google Cloud has that model coming soon to sit alongside the Gemini model family.
With that said, this is not the entire story. Enterprises require more than a generative AI model for moving use cases into production. Microsoft Azure still has the broadest set of complementary services. However, the biggest gap in the stack was the model performance. The other services will be easier to backfill.
Competition among LLM providers is about to get more interesting. The biggest unknown at the moment is when GPT-5 will be released (or GPT-4.5) and how much it will raise the performance bar. Epoch 2 of the LLM wars has arrived.

Google Goes Big on Context with Gemini 1.5 and Dips Into Open-Source with Gemma

Google has been busy well beyond fixing the system prompt issues for Gemini image generation. Gemini 1.5 is not just an upgrade of the Gemini model. It’s an entirely new model architecture. It arrives with a baseline 128k context window. However, Google is stressing that it has an eye-popping one million token context window currently being evaluated by…
Mistral Introduces Two New High Performance LLMs and Neither Are Open-Source

There is a lot to unpack in the new AI foundation models Mistral Large and Mistral Small. While Mistral’s earlier models debuted with open-source licenses, the new releases are…