

Grok-1.5 Closes Gap with OpenAI, Google, and Anthropic, Aces Long Context Window Retrieval
An API to access Grok-1.5 can't be too far away


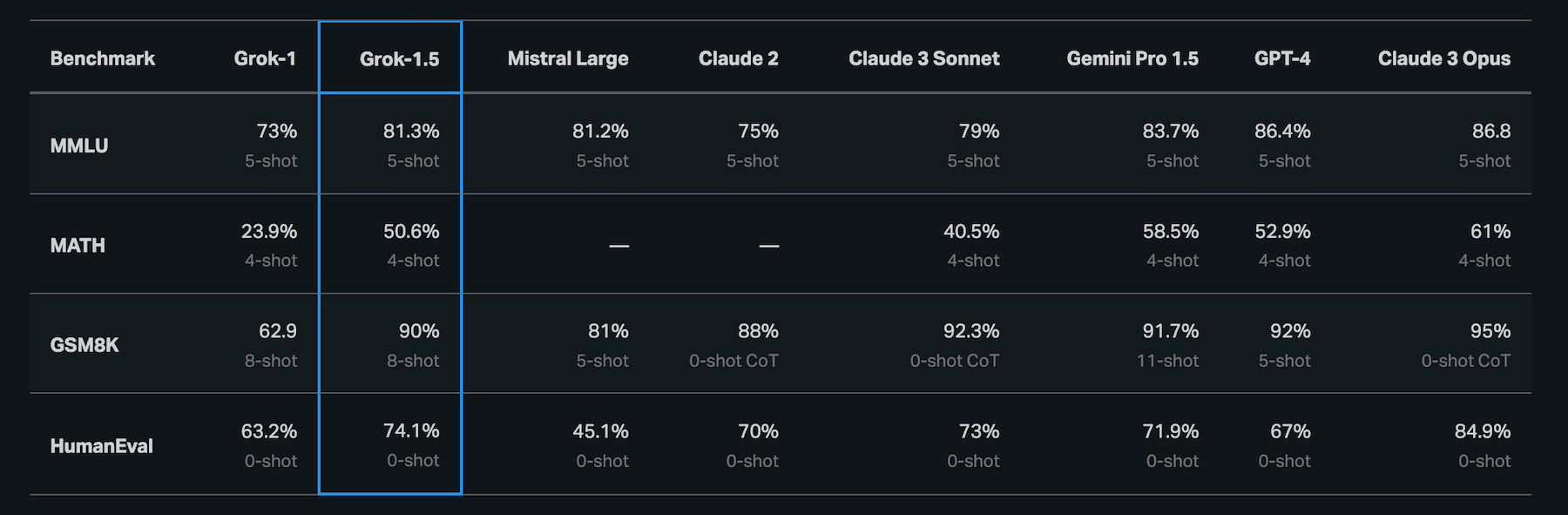
X.ai announced the Grok-1.5 large language model (LLM) Thursday, and it reflects a significant performance and feature upgrade over the now open-source Grok-1 model. Caveats aside about what benchmark results LLM developers choose to present, MMLU, MATH, GSM8K, and HumanEval results rose from Grok-1 to Grok-1.5, from 73% to 81.3%, 23.9% to 50.6%, 62.9% to 90%, and 63.2% to 74.1%, respectively. These results also outpaced Mistral Large and Anthropic Claude 2 figures.
Grok-1.5 also largely beats out Claude 3 Sonnet while marginally trailing Google Gemini Pro 1.5 and OpenAI GPT-4. Claude 3 Opus still shows a significant lead. Although now presented by X.ai, Grok-1.5 also compared favorably with DBRX from Databricks. Grok-1.5 performance was significantly higher for GSM8K and slightly better for MMLU and HumanEval.
According to X.ai, Grok-1.5 has improved significantly in coding and mathematics.
One of the most notable improvements in Grok-1.5 is its performance in coding and math-related tasks. In our tests, Grok-1.5 achieved a 50.6% score on the MATH benchmark and a 90% score on the GSM8K benchmark, two math benchmarks covering a wide range of grade school to high school competition problems. Additionally, it scored 74.1% on the HumanEval benchmark, which evaluates code generation and problem-solving abilities.
Long Context Retrieval Perfection
X.ai has come a long way in about nine months. Many of its rivals have been developing their foundation models and team expertise for years. The upgrade from Grok-1 to 1.5 is impressive, as is the narrowing of the performance gap to the frontier foundation models, such as GPT-4 and Claude 3 Opus. However, the most interesting data may be the long context retrieval results.

Grok-1.5 has a 128k token context window. This reflects a significant difference from other open models, such as DBRX and Mistral. The context window is the number of tokens the model can hold in memory while performing tasks. Anthropic, Google, and OpenAI both offer larger context window options in some of their models. However, 128k is significant.
Anthropic has published data about content retrieval or recall capabilities in long context windows. Typically, Anthropic models have performed relatively well recalling information in the first and last thirds of the context window while showing lesser results in the middle third. Grok-1.5 seems to have no such shortcomings.
A new feature in Grok-1.5 is the capability to process long contexts of up to 128K tokens within its context window. This allows Grok to have an increased memory capacity of up to 16 times the previous context length, enabling it to utilize information from substantially longer documents.
Furthermore, the model can handle longer and more complex prompts, while still maintaining its instruction-following capability as its context window expands. In the Needle In A Haystack (NIAH) evaluation, Grok-1.5 demonstrated powerful retrieval capabilities for embedded text within contexts of up to 128K tokens in length, achieving perfect retrieval results.
Moving Toward Model APIs
Grok-1.5 is not yet available, though the company is working with early model testers. Today, users can access the open-source Grok-1 model directly and use it as they wish. Grok-1.5 will first power the Grok assistant, a rival solution to ChatGPT and Inflection’s Pi.
Synthedia expects X.ai to soon begin offering the 1.5 model to users as an inference API. That will be more of a test for the leading LLMs than the existing Grok assistant. The question is whether enterprise users would prefer an open-source alternative like Grok or whether they are content using proprietary models. It appears that most of the market adoption data show far more growth for proprietary model developers. For companies that favor open-source, it may be that X.ai’s offering is more compelling than Meta Llama or Mistral and also compares favorably to leading proprietary models.

Databricks Claims a Performance Lead with a New Open LLM

Databricks has announced a new open large language model (LLM) called DBRX that it says handily beats the Llama 2, Mistral, and Grok-1 open models in performance benchmarks. DBRX is a 132 billion parameter mixture-of-experts LLM trained on 12 trillion data tokens.
X.ai's Grok-1 Model is Officially Open-Source and Larger Than Expected

X.ai announced today that the Grok 1 large language model (LLM) is officially available under the open-source Apache 2.0 license. This permissive license allows users royalty-free access to the source code for commercial and private uses. According to
100% retrieval accuracy on the Needle-in-a-Haystack test in a 128k token context window? I know these are test conditions, but that’s very positive news for RAG type of applications, no?