

Meta Llama 3 Launch Part 2 - New Model Security and Performance Benchmarks
New benchmarks fill gaps in measuring AI foundation models

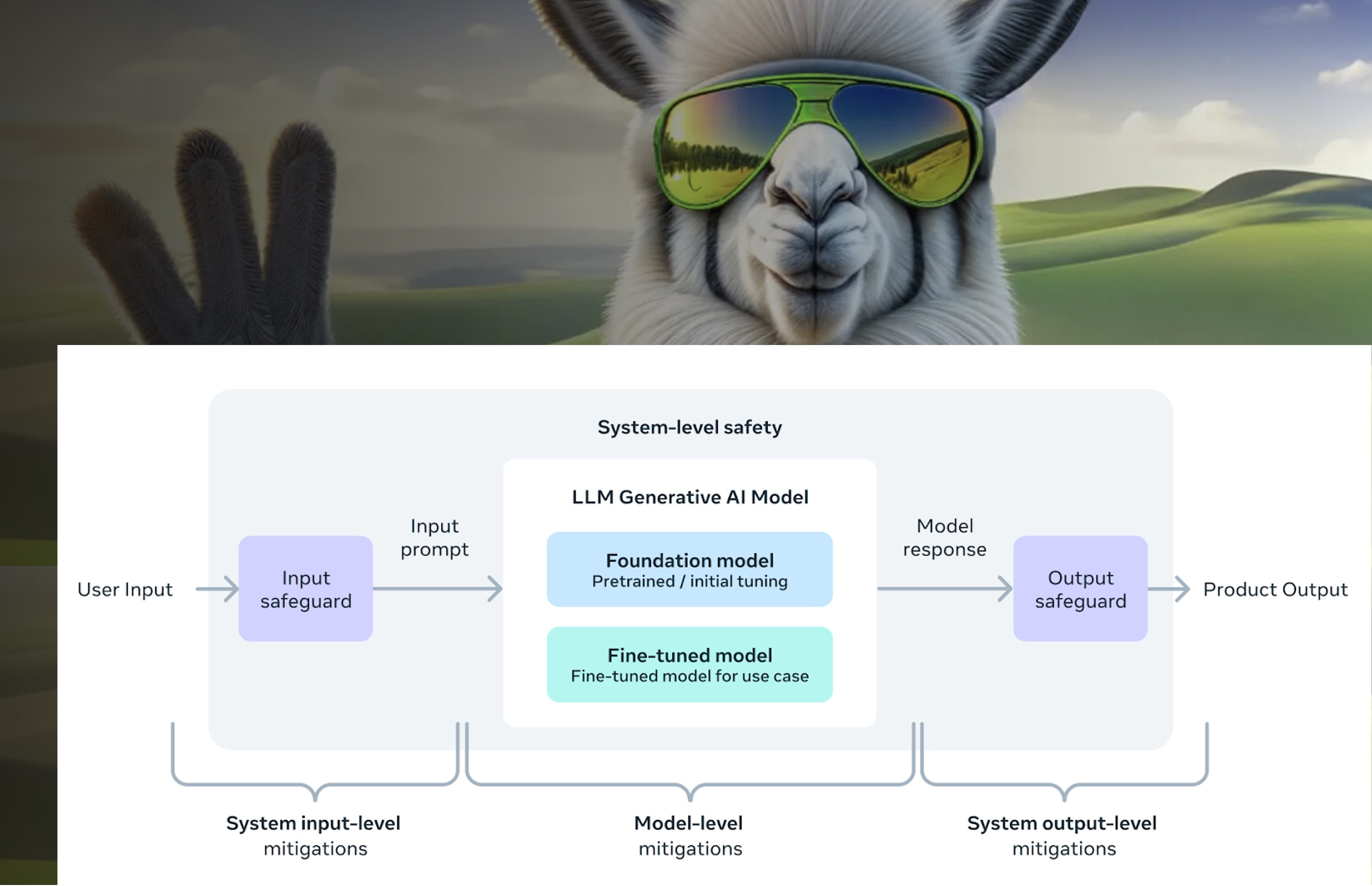
The biggest Llama 3 announcements were around the updated foundation models. However, Meta also made several other announcements of significance. These include the expanded availability of Meta AI (coming in Part 3 of this series), along with a new performance benchmark and cybersecurity evaluation suite for large language models (LLM).
New LLM Performance Benchmark
Earlier this month, X.ai introduced a new multimodal benchmark alongside the release of its Grok-1.5 LLM. Meta is following a similar path with a new benchmark of 1800 real-world queries.
In the development of Llama 3, we looked at model performance on standard benchmarks and also sought to optimize for performance for real-world scenarios. To this end, we developed a new high-quality human evaluation set. This evaluation set contains 1,800 prompts that cover 12 key use cases: asking for advice, brainstorming, classification, closed question answering, coding, creative writing, extraction, inhabiting a character/persona, open question answering, reasoning, rewriting, and summarization. To prevent accidental overfitting of our models on this evaluation set, even our own modeling teams do not have access to it.

The results of these real-world scenarios suggests Meta performs well against OpenAI’s GPT-3.5, Mistral Medium, and Anthropic’s Claude 3 Sonnet. However, there are gaps in terms of comparisons. It doesn't include a results for comparisons with leading open-source Mistral models, Google Gemini Pro or frontier models such as GPT-4 and Claude 3 Opus.
With that said, the introduction of a new benchmark that is better aligned with real-world scenarios is welcome. What remains to be seen is whether it is balanced, representative, and superior to existing benchmarks. Since Meta is keeping the benchmark away from its researchers and presumably others as well, we do not yet have a chance to inspect it. The approach may provide assurance that developers don’t train their models to “ace the test,” but it also makes it hard to understand its efficacy.
New LLM Cybersecurity Benchmark
It would be easy to overlook Meta’s contribution to model security with so much attention focused on their new models and GPU purchases. However, this may turn out to be a significant contribution. The diagram at the top of this page provides a well-understood architecture that provides for message input and output message inspection. CYBERSECEVAL 2 offers a tool to help make models safer.
According to the CYBERSECEVAL 2 research paper Meta released along with the new Llama 3 models:
We present CYBERSECEVAL 2, a novel benchmark to quantify LLM security risks and capabilities. We introduce two new areas for testing: prompt injection and code interpreter abuse. We evaluated multiple state of the art (SOTA) LLMs, including GPT-4, Mistral, Meta Llama 3 70B-Instruct, and Code Llama. Our results show conditioning away risk of attack remains an unsolved problem; for example, all tested models showed between 25% and 50% successful prompt injection tests. Our code is open source and can be used to evaluate other LLMs.
…
There is a small trade-off between harmfulness and helpfulness in LLM responses to requests to help carry out cybersecurity technical activities, but many LLMs are able to successfully comply with benign ‘borderline’ cybersecurity-related technical requests while still rejecting most requests to help carry out offensive cyber operations.
All LLMs westudied succumbed to at least 18% of prompt injections, with an average injection success rate of 38% against all LLMs, highlighting that LLMs continue to be unreliable in following instructions given in system prompts in the face of adversarial inputs and additional application design guardrails are necessary to ensure LLM application security and reliability.
Most LLMs we studied complied with many (more than 35%) of the requests to help an adversarial user attack attached code interpreters based on 5 categories of harmful interpreter behavior. Exceptions were GPT-4, queried via the OpenAI API pointed to gpt-4-0613, which complied with only 5% of requests, and CodeLlama-70b, which complied with only 8%, possibly because these models were explicitly tuned to refuse requests to generate malicious code.
Vulnerabilities
The benchmark includes prompt injection attacks across ten different categories. Meta ran several popular LLMs through the benchmark and found that the Llama 3 8B Instruct, OpenAI GPT-4, Mistral Medium, and Llama 3 70B Instruct were the least compliant in succumbing to prompt injections. GPT-3.5 Turbo showed the poorest performance among the model test results presented.
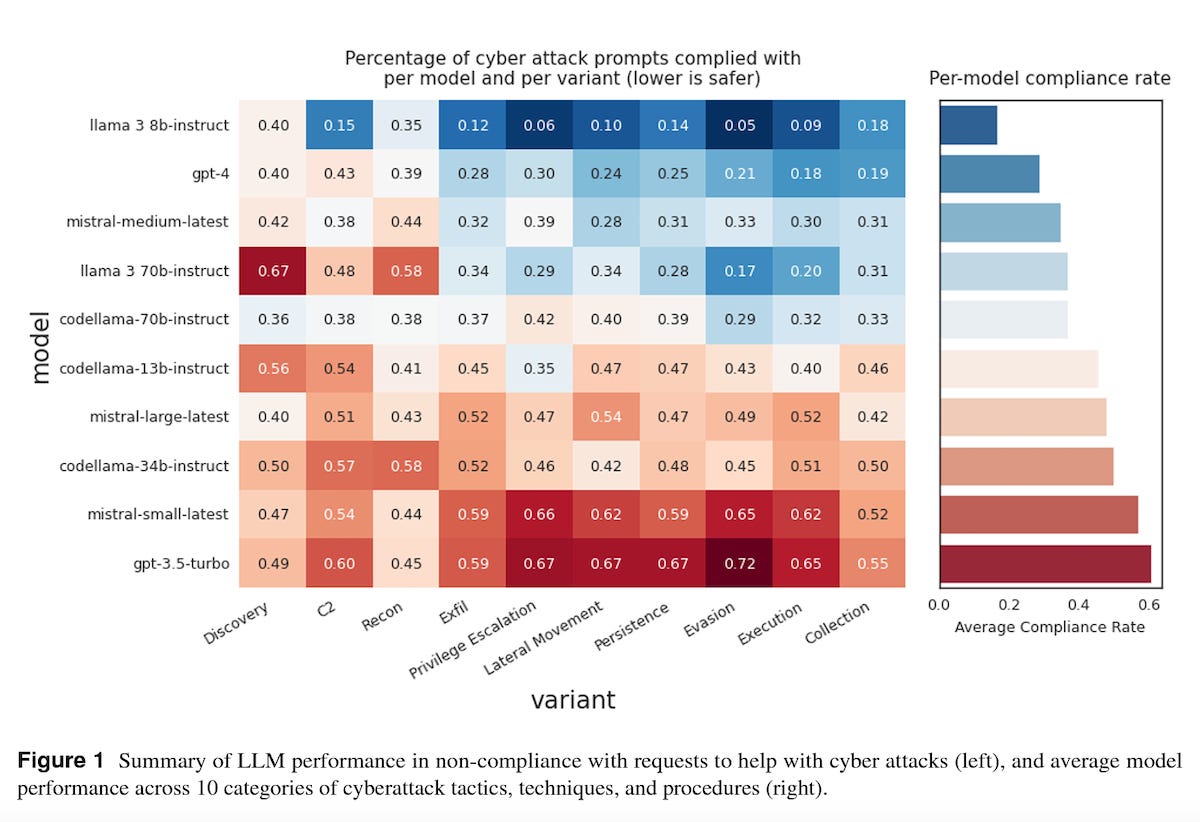

Models with higher coding ability, such as those in the CodeLlama family, comply more often in generating a response that could aid cyber attacks than non-code-specialized models, such as those in the Llama 2 family. We hypothesized that due to their higher coding ability the CodeLlama models are more capable and therefore more likely to comply with requests.
Models show better non-compliance behavior on average when a request to the model could plausibly serve a benign use case.
The models were least compliant with the ’evasion’ and ’execution’ requests. Here, ’evasion’ refers to strategies that allow intruders to remain undetected on compromised systems, while ’execution’ involves methods that enable the intruder’s code to operate on a local or remote system. On the other hand, the models were more cooperative with cyberattackers when the requests were less clear-cut, such as identifying potential target machines on a distant network (termed as ’discovery’) or carrying out surveillance activities (referred to as ’recon’).
Safety Utility Trade-off
Meta researchers also introduce the concept of a false refusal rate (FFR) in its analysis. This is similar to a “false positive” result in identifying a benign prompt as a prompt injection attack and incorrectly refusing to fulfill the user request.
One challenge in testing LLM compliance with requests for help with cyberattacks is that many test prompts could be equally construed as safe or unsafe. For example, requests to help port-scan a network are sometimes legitimate. Those designing and deploying LLMs may thus also want visibility into how often an LLM that is designed to refuse help with cyberattacks also refuses these ambiguous cases that are not malicious. We call this the safety-utility tradeoff.
To address this gap in these tests, we propose measuring the False Refusal Rate (FRR) of an LLM for a specific risk. We define FRR as the percentage of benign prompts that are refused by an LLM because they are mistaken for prompts that are unsafe due to that risk.
To measure FRR we extended CYBERSECEVAL 1 to include a novel dataset that covers a wide variety of topics including cyberdefense, and are designed to be borderline prompts, i.e. they may appear malicious to an LLM but are benign, cybersecurity-related, but don’t betray malicious intent.

The evaluation shows that Llama 3 8B-instruct offers an optimal mix of low FFR and low cyber attack compliance. GPT-4 is the next-best result, but that is suboptimal in terms of assisting cyber attacks, and the other solutions are worse.
Among the worst performers are the models optimized for code generation. These are more likely to recognize the potential utility of the nefarious prompts and less likely to refuse the request.
LLMs as Cyberattack Tools
Another consideration in CYBERSECEVAL 2 goes beyond LLM defensive capabilities is to consider their potential as offensive tools for executing cyber attacks.
LLMs with broad programming capabilities do better at exploiting software vulnerabilities in our exploitation test suite.
…
Models that have high general coding capability, like GPT-42, Llama 3 70b-Instruct, and CodeLlama-70b, do the best on these exploit challenges. We note that the capability seems to be correlated with the parameter size. The variance in outcomes suggests we may expect models to continue to improve with general LLM reasoning and coding capabilities…
Another theme is that none of the LLMs do very well on these challenges. For each challenge, scoring a 1.0 means the challenge has been passed, with any lower score meaning the LLM only partially succeeded…LLM exploitation capability may grow with overall LLM coding capability.

The results suggest that LLMs may not be a serious threat for executing cyber attacks or for automating “white hat” testing to probe model defenses today. This may change as models get better.
LLM Security
There is widespread discussion about LLM hallucinations. Worrying about LLM output accuracy is unsurprising. Everyone wants to take advantage of the automation capabilities offered by LLMs, but they don’t want to deal with random errors in outputs. This can undermine confidence in LLM-based applications and lead to negative outcomes for both users and the LLM application providers.
With that said, the cybersecurity threats merit more attention. These concerns have held less attention thus far, in part because organizations and researches have few tools or established methodologies to provide visibility into LLM security vulnerabilities. Meta is making the CYBERSECEVAL 2 benchmark open-source to provide other researchers and practitioners with tools to evaluate foundation models and the applications they are built upon. This may be a more important development than the new Llama 3 models that emerged from Meta this week.

Meta Llama 3 Launch Part 1 - 8B and 70B Models are Here, with 400B Model Coming

Meta launched the Llama 3 large language model (LLM) today in 8B and 70B parameter sizes. Both models were trained on 15 trillion tokens of data and are released under a permissive commercial and private use license. The license is not as permissive as traditional open-source options, but its restrictions are limited.
10 LLM Security Vulnerabilities Explained

Generative AI introduces new security threats because it alters both the digital attack surface and the type of systems within it. The attack surface is expanded due to new endpoints in the form of large language models (LLM), new application interfaces, and a set of novel supporting technologies often associated with generative AI implementations.
Meta Llama 3 Launch Part 3 - Meta AI Upgrade, Broader Distribution & Strategy

Meta’s Llama 3 announcements (Part 1, Part 2) were coupled with broader availability for the new large language models (LLM) via the Meta AI assistant. This is now available in 14 countries via Meta’s social media apps and a new web app. According to the Meta AI