

Microsoft's New Phi-2 Small LLM Shows Strong Benchmark Performance
SLMs typically trail LLMs in performance but are more cost efficient


Microsoft is excited about small language models (SLM). The company refers to LLMs below 13B parameters as small large language models (SLM). There is no industry standard for this, but Mistral also calls its new Mixtral 8x7B model small and its 7B model tiny. Regardless, these are all transformer models with a few billion parameters.
Phi-2 is Microsoft’s latest entry into the SLM category and follows earlier models, Phi-1 and 1.5. The new model has 2.7 billion parameters (2.7B) and was trained on 1.4 Trillion (1.4T) tokens. The curated training data is a key reason why the new model performs so well on common industry benchmarks.
Outpacing Llama 2
In reporting the industry benchmark data, Microsoft researchers compared the results to the Llama 2 7B, 13B, and 70B models, along with Mistral’s 7B model, launched in September. The new Mixtral 8x7B mixture of experts (MoE) model from Mistral was not included in the reported data, likely because the model just became available this week.
From a reporting standpoint, Microsoft obscures some of the benchmark data by showing averages of several baskets of benchmarks. However, it did report Big Bench Hard (BBH) and GSMK8 in the Math category separately. In the commonsense reasoning basket, Microsoft included PIQA, WinoGrande, ARC easy and challenge, and SIQA. The language understanding basket included HellaSwag, OpenBookQA, MMLU (5-shot), SQuADv2 (2-shot), and BoolQ. HumanEval and MBPP were used for the Coding basket.
Each model developer decides what benchmarks it wants to present as part of their model performance results. This means a wide variety of reporting metrics that can be difficult to compare on an apples-to-apples basis. Regardless, Phi-2 looks like a strong performer.
Phi-2 bested the two smaller Llama 2 models in each category despite having about one-third to one-fifth the number of parameters. It also bested the Mistral 7B model (sometimes called Tiny) in each of the test categories except for language understanding. The Math category (GSM8K) was also reported by Mistral separately at 58.4%, so it seems Phi-2 also wins in that category. Unfortunately, we are not able to provide additional direct comparisons with Mixtral 8x7B.
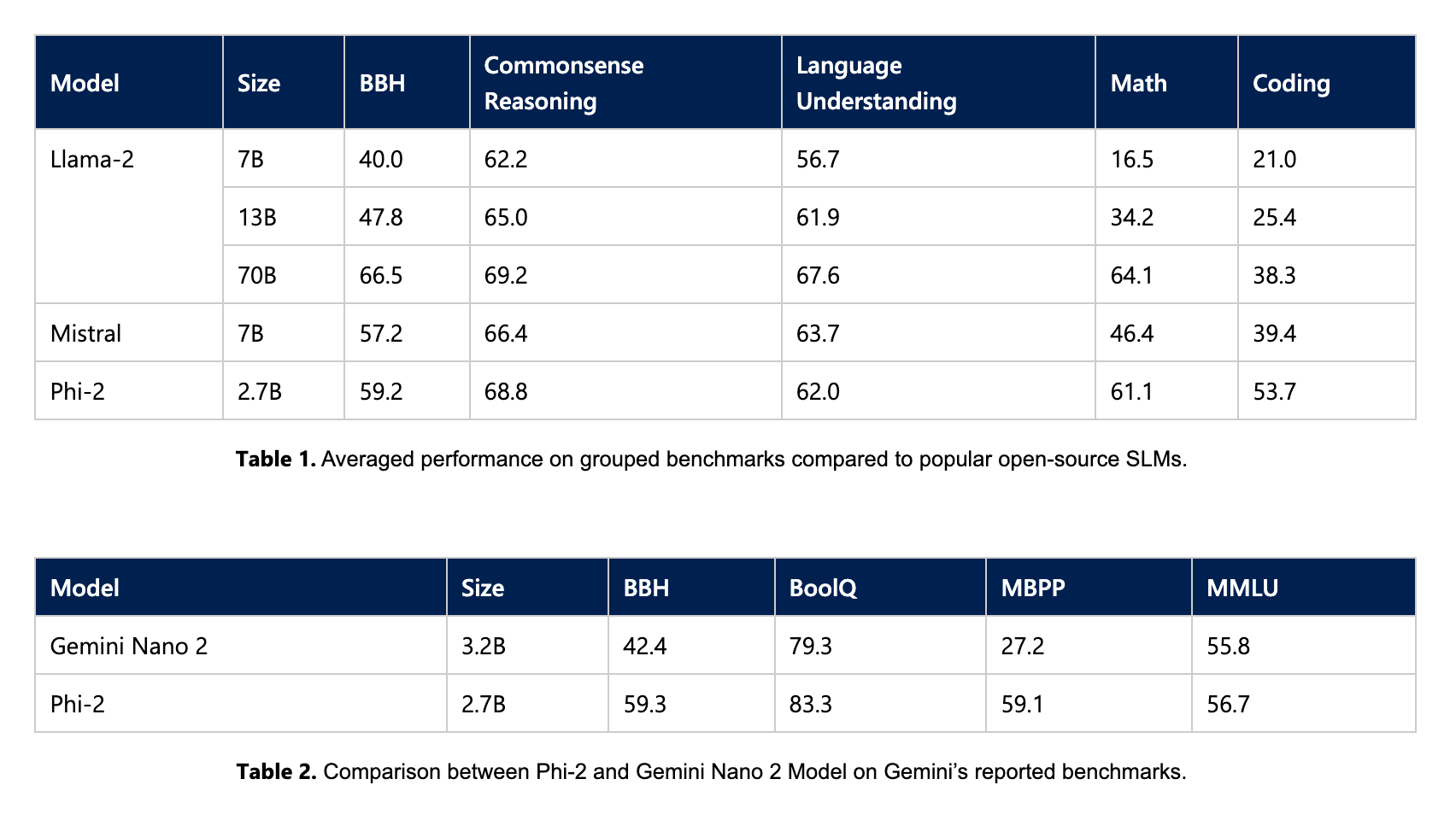
Microsoft also directly compared Gemini Nano 2, the smallest of the forthcoming Gemini LLMs from Google. The data show Phi-2 beating Nano-2 in BBH, MBPP, BoolQ, and MMLU, with significantly higher performance for the first two.
To highlight Phi-2’s reasoning capabilities, Microsoft provided an example of a math word problem. It also showed a separate example of the SLM reviewing a student’s math problem and identifying the error that was made.

Training is All you Need
New architectures, such as MoE, are getting a lot of attention 😀 from researchers. This follows the race to larger and larger parameter counts that characterized LLMs from 2018 until early 2023. Today, there is more focus on developing SLMs that have comparable or reasonably similar performance as the giant frontier models.
Microsoft’s researchers emphasized how important they believe data quality (and scale) are to model performance. The blog post noted earlier research named Textbooks are All You Need that evaluated the impact of refined datasets on performance.
Firstly, training data quality plays a critical role in model performance. This has been known for decades, but we take this insight to its extreme by focusing on “textbook-quality” data, following upon our prior work “Textbooks Are All You Need.” Our training data mixture contains synthetic datasets specifically created to teach the model common sense reasoning and general knowledge, including science, daily activities, and theory of mind, among others. We further augment our training corpus with carefully selected web data that is filtered based on educational value and content quality. Secondly, we use innovative techniques to scale up, starting from our 1.3 billion parameter model, Phi-1.5, and embedding its knowledge within the 2.7 billion parameter Phi-2. This scaled knowledge transfer not only accelerates training convergence but shows clear boost in Phi-2 benchmark scores.
After training, the model alignment was pursued via reinforcement learning with human feedback (RLHF), as with most other recently released LLMs.
The Incredibly Shrinking LLMs
Bigger is generally better when it comes to LLM performance. However, there is a lot of research seeking to close the performance gap between LLMs and SLMs. The reasons for this pursuit are three-fold.
SLMs cost less to train than LLMs
SLMs cost less to operate through inference than LLMs
SLMs generally show lower latency than LLMs.
The giant models are a reasonable choice for proof-of-concept pilots and some production systems. However, the cost of using them at scale has led many researchers to focus more on cost efficiency. Phi-2 is one you should consider if cost-efficient generative AI is a key requirement for your use case.

Mistral Has $415M in New Funding, a Big Valuation, and a New LLM to Challenge GPT-4

Editor’s Note: Updates were added on December 11 based on newly released company information about the models and an API service. Numerous media outlets report that Mistral has just closed a $415 million funding round at a $2 billion valuation. The company also released its latest large language model (LLM) on Friday by posting a to…
Google's Gemini LLM Arrives Next Week and It May Just Outperform GPT-4 (sort of)

Google CEO Sundar Pichai announced in a blog post that the Gemini large language model (LLM) will launch next week as an API in Google AI Studio and Vertex AI in Google Cloud. The solution is regarded as a replacement for the company’s current flagship LLM, PaLM. This represents the third LLM product family that Google has used this year, including the …