

Microsoft's Phi AI Models Show it is Not Just an OpenAI Reseller
Phi is accessible on Azure and Hugging Face and carries an open-source license

Microsoft invested billions of dollars in AI research before investing a cumulative $13 billion in OpenAI. The company has long been a leader in AI research. Still, it was slower than Google to shift its efforts to developing autoregressive large language models (LLM) based on attention mechanisms. That may have been a blessing. It led to the company’s OpenAI investments as a hedge and an exclusive arrangement with the most popular LLM portfolio in the market.
Its OpenAI foundation model exclusivity among the leading cloud hyper scalers is Microsoft’s biggest asset in the hyper-competitive LLM segment. However, Microsoft is not solely betting on OpenAI. The company executed an unusual partnership and aquihire of the management leadership and much of the engineering team from OpenAI competitor Inflection AI in March. Last fall, it debuted a new small language model (SLM) called Phi. That product has evolved.
Phi-3
Microsoft just announced the first of its Phi-3 SLMs, starting with Phi-3-mini, a 3.8 billion parameter model. Public benchmark data released by Microsoft suggests that the Phi-3 model family is comparable to or better than small, open model competitors.
We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
Additional details from this week’s announcement include:
Starting today, Phi-3-mini, a 3.8B language model is available on Microsoft Azure AI Studio, Hugging Face, and Ollama.
Phi-3-mini is available in two context-length variants—4K and 128K tokens. It is the first model in its class to support a context window of up to 128K tokens, with little impact on quality.
It is instruction-tuned, meaning that it’s trained to follow different types of instructions reflecting how people normally communicate. This ensures the model is ready to use out-of-the-box.
It is available on Azure AI to take advantage of the deploy-eval-finetune toolchain, and is available on Ollama for developers to run locally on their laptops.
…
In the coming weeks, additional models will be added to Phi-3 family to offer customers even more flexibility across the quality-cost curve. Phi-3-small (7B) and Phi-3-medium (14B) will be available in the Azure AI model catalog and other model gardens shortly.
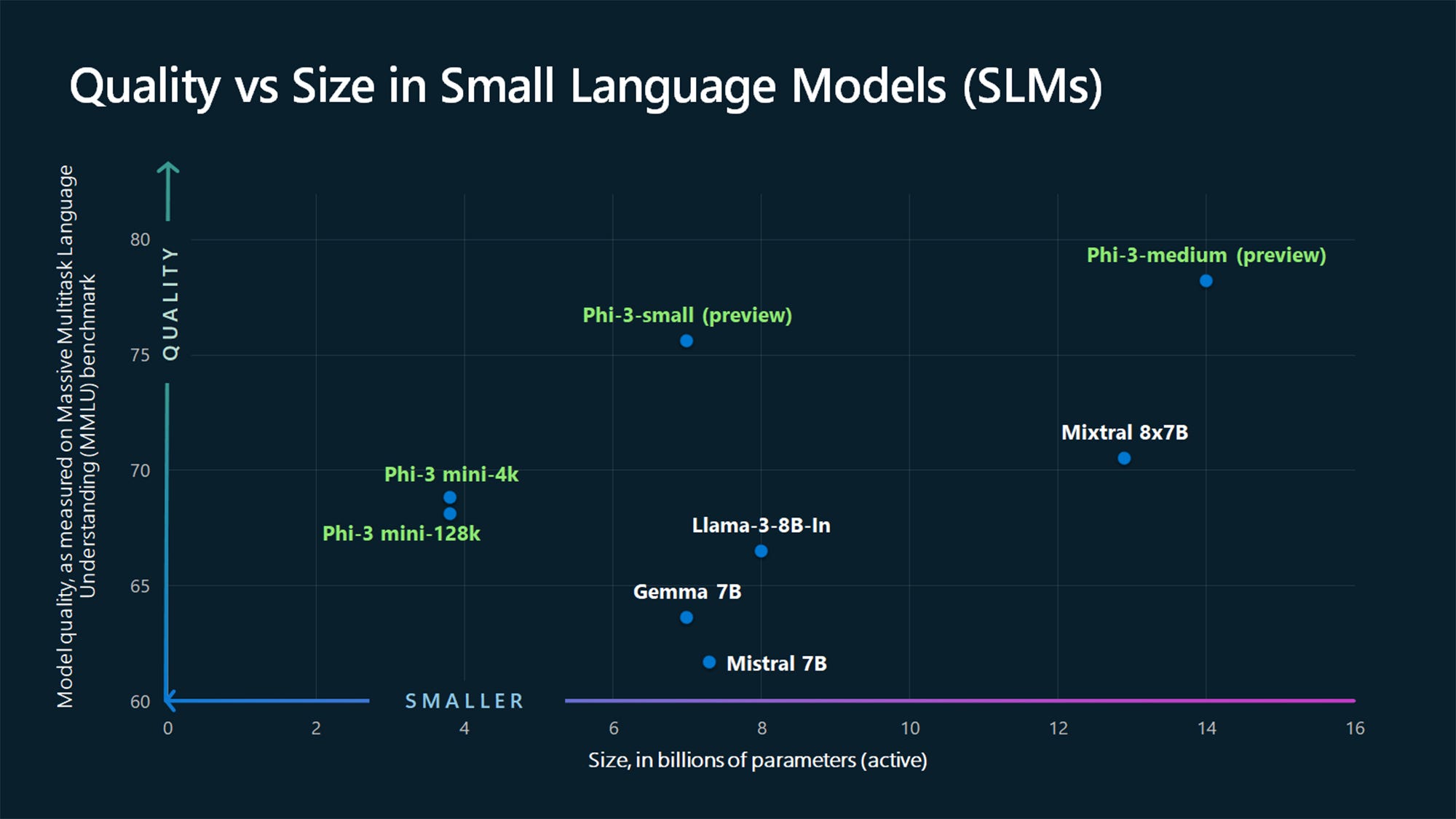
The Phi-3 models show remarkable improvement in public performance benchmarks over the Phi-2 version. They also compare favorably and typically perform better than other comparable-sized models such as Llama 3 Instruct, Mixtral 8x7B, and even the larger and proprietary GPT-3.5.
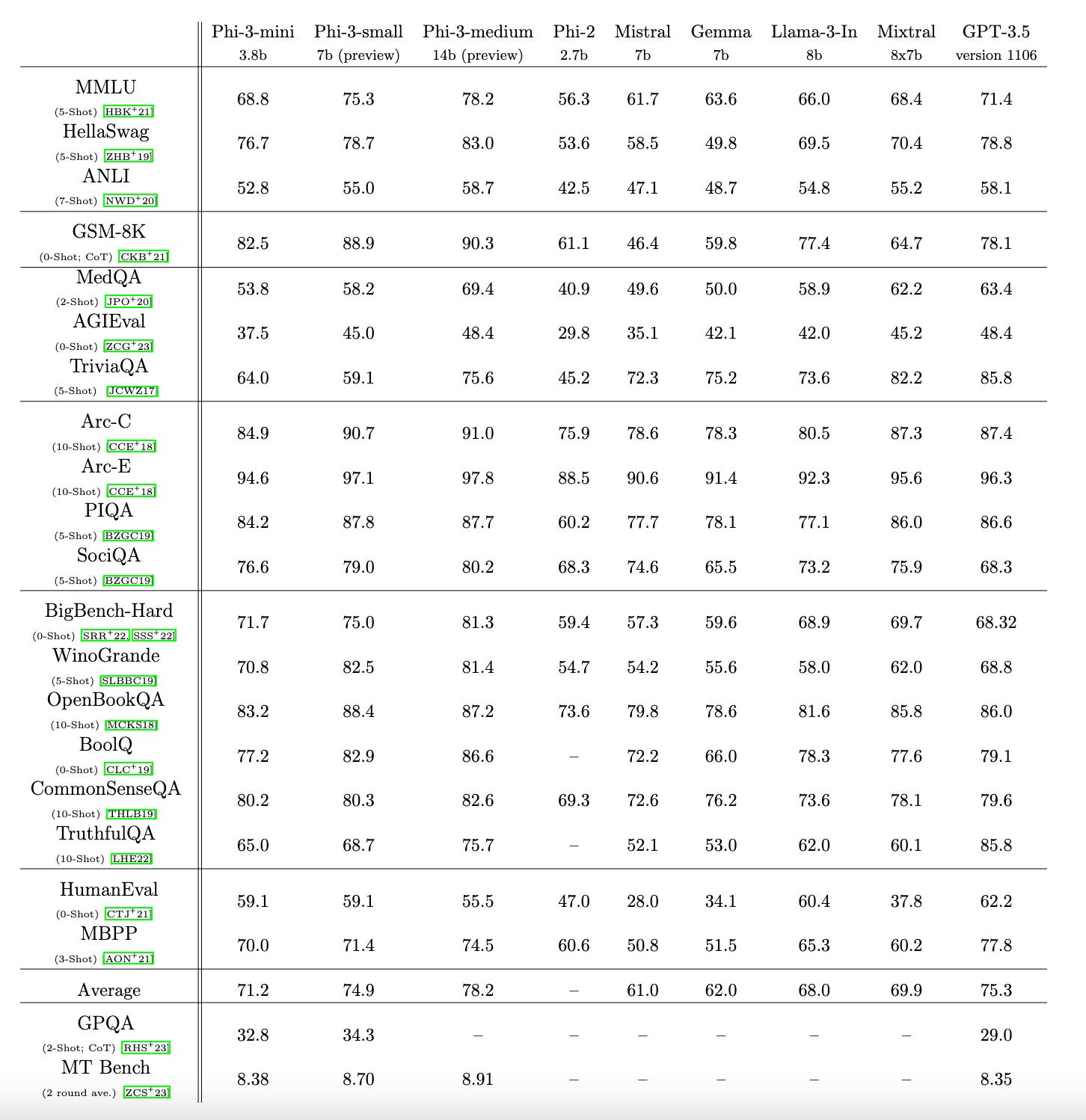
Microsoft does provide a disclaimer about the smaller models and performance on fact-based benchmarks. According to company researchers, “Phi-3 models do not perform as well on factual knowledge benchmarks (such as TriviaQA) as the smaller model size results in less capacity to retain facts.” The data above confirm this contention. As the Phi model parameter count rises, success in fact-based benchmarks rises.
This is evident in the chart at the top of the page, which compares various LLMs' MMLU benchmark scores. However, size isn’t the only factor that matters. Phi models outperform their peers even with fewer parameters.
The factuality challenge is also a likely reason why the two smallest models are much worse than the 14B model in the fact-based benchmarks. When it comes to trivia, data does not overcome a lack of parameters.
Microsoft’s experience shipping copilots and enabling customers to transform their businesses with generative AI using Azure AI has highlighted the growing need for different-size models across the quality-cost curve for different tasks. Small language models, like Phi-3, are especially great for:
Resource constrained environments including on-device and offline inference scenarios.
Latency bound scenarios where fast response times are critical.
Cost constrained use cases, particularly those with simpler tasks.
Thanks to their smaller size, Phi-3 models can be used in compute-limited inference environments.
All Those Tokens
Note that Microsoft researchers attributed much of the model performance gains as driven by the dataset used in training. Synthedia reported in 2023 that model performance gains, once driven primarily by total model parameters, were starting to show dimishing marginal returns. Google was among the first to recognize that adding more training tokens significantly improved performance of models of all sizes.
The scaling of total training tokens was followed by a wave of new architectures, particularly Mixture of Experts (MoE) approaches, that were responsible for new performance gains. In 2023, Sam Altman indicated on the Lex Fridman podcast that curated data was the secret to the next wave of improvements. Altman stated, “A lot of our work is building a great dataset.” Microsoft is following a similar path in its approach. According to its research paper released this week:
We follow the sequence of works initiated in “Textbooks Are All You Need”, which utilize high quality training data to improve the performance of small language models and deviate from the standard scaling-laws. In this work we show that such method allows to reach the level of highly capable models such as GPT-3.5 or Mixtral with only 3.8B total parameters (while Mixtral has 45B total parameters for example). Our training data of consists of heavily filtered web data (according to the “educational level”) from various open internet sources, as well as synthetic LLM-generated data.
The research paper’s title, “Textbooks Are All You Need,” is an homage to the seminal research titled “Attention is All You Need,” which kicked off the generative AI innovation wave. The “Textbooks” research from 2023 stated:
In this work, following the footsteps of Eldan and Li, we explore the improvement that can be obtained along a different axis: the quality of the data. It has long been known that higher quality data leads to better results, e.g., data cleaning is an important part of modern dataset creation, and it can yield other side benefits such as somewhat smaller datasets or allowing for more passes on the data. The recent work of Eldan and Li on TinyStories (a high quality dataset synthetically generated to teach English to neural networks) showed that in fact the effect of high quality data extends well past this: improving data quality can dramatically change the shape of the scaling laws, potentially allowing to match the performance of large-scale models with much leaner training/models.
Data curation is important. A smaller amount of low-quality data reduces the risk of low-quality outputs. In addition, Microsoft researchers in both papers listed above also added synthetic data to the training dataset. The Phi-3 benchmark data represents an interesting empirical example of synthetic data improving model performance. This may be a particularly important finding for developers focused on specialty models where the depth of available data may be too limited to train a robust model. Synthetic data could be employed to fill that data gap.
Open Models
Note also that Phi-3 are open models issued under a permissive MIT open-source license. While the large proprietary models such as OpenAI’s GPT-4 and Anthropic’s Claude 3 Opus get most of the media attention, open models from Meta, Mistral, Google, Databricks, and X.ai have shown significant performance gains.
This aligns with corporate buyer interest in using AI models that offer more control. The proprietary LLMs are black box products that offer limited customization options, and inference fees can quickly become expensive. It is not “free” to run open models because you have to pay for the computing costs. However, they do not carry license fees, token costs, or subscriptions. Users pay to operate them, and they can typically make modifications.
There are not a lot of companies using open models today for production use cases. However, this will inevitably change. The key barrier is a lack of technical talent required to set-up and operate LLMs in-house. This is why Azure and Google Cloud offer hosting for these models and often APIs. It reduces a key barrier to adoption. Open-source licensing often mitigates objections from legal teams about IP ownership, privacy protection, and security concerns.
Microsoft’s Strategy
Microsoft has the enviable position of market share leadership. This was largely established on its exclusivity with the popular and (at the time and maybe still today) industry-leading AI foundation models from OpenAI coupled with an easy onramp into the well-regarded Azure cloud service. Microsoft has also integrated generative AI into its business productivity software and consumer products.
More recently, Microsoft has also been moving to reduce its dependence on OpenAI. Arrangements in 2023 with Meta began the trend, while recent deals with Mistral and Inflection have given the trend more momentum. The Phi-3 models continue down that path. It provides a trusted source of SLMs for business use cases that do not require the computing overhead, cost, and latency of LLMs with hundreds of billions of parameters. The move may also open up new consumer use cases on portable devices like smartphones.
At some point, you may see Microsoft software and services leveraging SLMs like Phi in its products as the primary AI models or as specialty solutions. Most people don’t realize that production generative AI solutions often include multiple models operating simultaneously. There may be a large frontier AI model like GPT-4 handling the most complex and varied tasks. However, that will often be complemented by other models used for arbitration or moderation tasks. The emerging enterprise architecture for generative AI solutions will be a series of models with task specialization that complement a general purpose LLM and together enable orchestrated user request fulfillment.
Don’t be surprised if you start seeing specialty AI agent services that support generative AI applications built on top of Phi, Mistral, or Gemma.

How OpenAI's Former Board Inadvertently Created a New Competitor Inside its Patron

Microsoft CEO Satya Nadella published a blog post this week stating that Mustafa Suleyman and Karén Simonyan, two of Inflection AI's three co-founders, will join Microsoft to lead a newly created organization, Microsoft AI. According to Nadella: Mustafa Suleyman and Karén Simonyan are joining Microsoft to form a new organization called Microsoft AI, foc…
Meta Llama 3 Launch Part 1 - 8B and 70B Models are Here, with 400B Model Coming

Meta launched the Llama 3 large language model (LLM) today in 8B and 70B parameter sizes. Both models were trained on 15 trillion tokens of data and are released under a permissive commercial and private use license. The license is not as permissive as traditional open-source options, but its restrictions are limited.