

Snowflake Jumps into Generative AI with a New LLM
The data platform has a Copilot, a new open-source LLM, and alternative to Databricks

Snowflake has announced a new large language model (LLM) in a move that mirrors Databricks’ strategy. Generative AI gravity will always tilt toward data. The rise of retrieval augmented generation (RAG) and large data token training sets are just two examples of how the knowledge revolution represented by LLMs is closely tied to data. Snowflake is a central player in the data ecosystem.
The company is positioning its new LLM Arctic as efficient and open. According to Snowflake:
Arctic excels at enterprise tasks such as SQL generation, coding and instruction following benchmarks even when compared to open source models trained with significantly higher compute budgets. In fact, it sets a new baseline for cost-effective training to enable Snowflake customers to create high-quality custom models for their enterprise needs at a low cost.
Apache 2.0 license provides ungated access to weights and code. In addition, we are also open sourcing all of our data recipes and research insights.
The most interesting elements of the new LLM go beyond the summary information above. The mere fact that Snowflake is the developer, combined with its novel model training approach and use of a hybrid architecture for a single model, are developments worth noting. Snowflake as the model developer is significant because database companies are now becoming LLM developers as opposed to just providing data sources for retrieval augmented generation (RAG) implementations. Training and model architecture innovation may point to additional innovations on the horizon for other LLM developers.
Performance
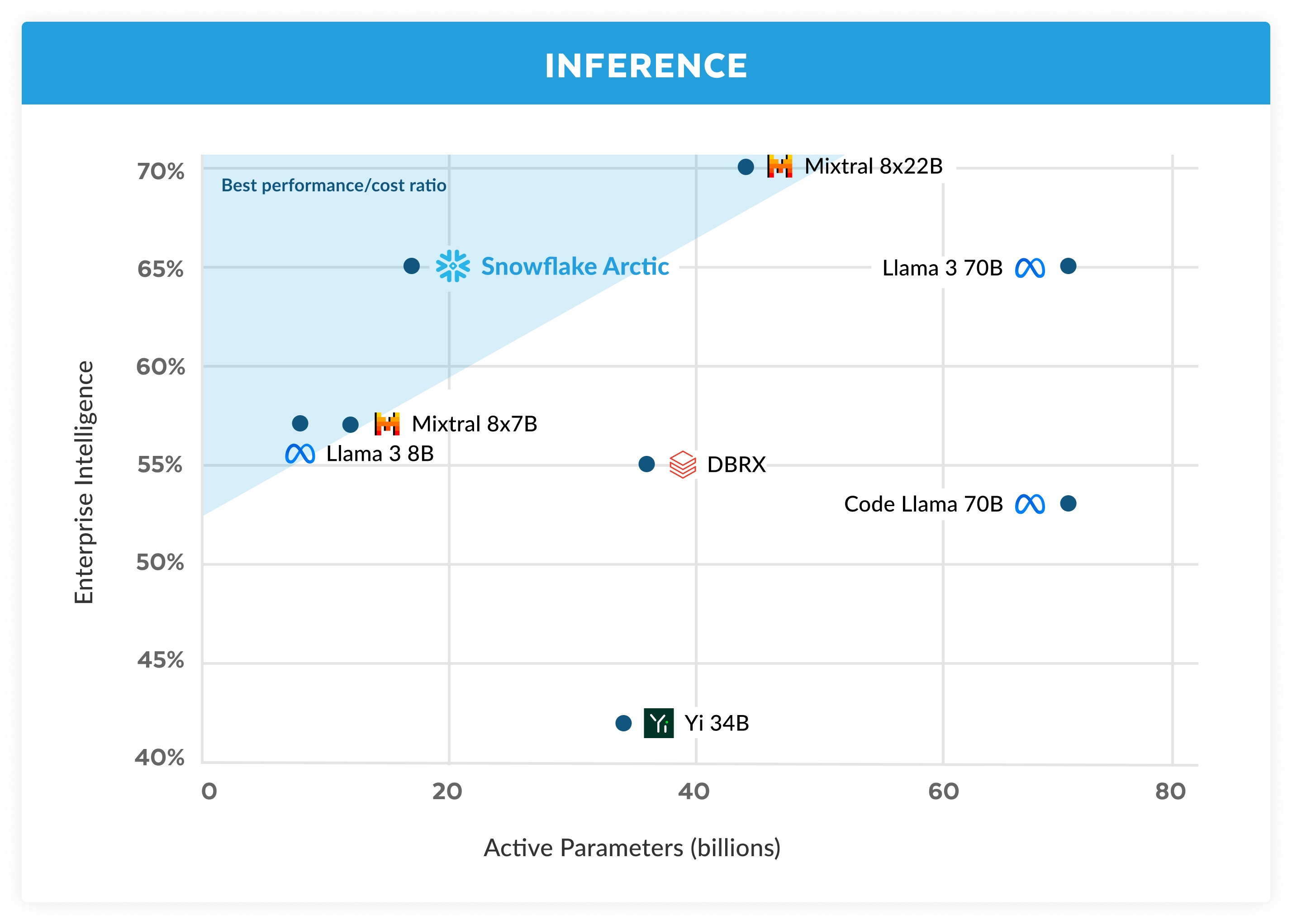
The claims behind Arctic’s performance are based on the results of a basket of four benchmarks that sum the “average of Coding (HumanEval+ and MBPP+), SQL Generation (Spider), and Instruction following (IFEval) vs. Active Parameters during Inference.”
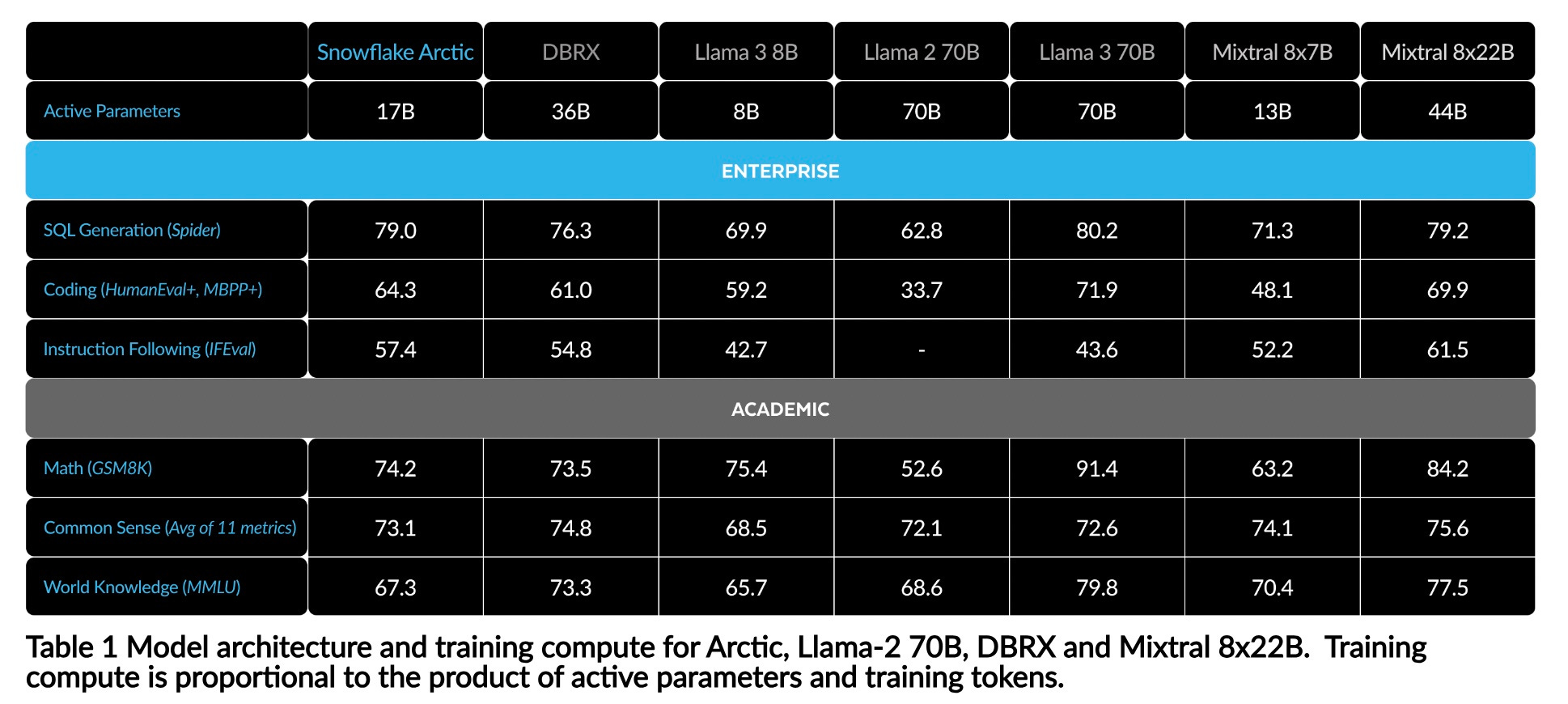
In addition, the announcement includes data on performance for GSM8K, Common Sense, and MMLU. The latter is the benchmark that nearly every model developer now reports. MMLU is the most commonly cited general-purpose benchmark and Arctic shows a meaningful gap to reported comparison models such as Databricks’ DBRX, Meta’s Llama 3 70B, and Mistral’s Mixtral 8x22B.
Arctic appears to be particularly strong in SQL generation, comparing favorably to Llama 3, and Mixtral 8x22B. That is no doubt helpful considering Snowflake’s core business.
The company’s presentation of Arctic as efficient on the basis of benchmark performance per active parameter is largely anchored in its use of a Mixture of Experts (MoE) LLM architecture compared to unified models (i.e., dense models), such as Llama. MoE architectures have typically offered both benchmark performance increases as well as higher computational efficiency at runtime due to the activation of fewer model parameters for each inference query.
SQL Benchmark
Every LLM provider is somewhat selective in its benchmark data presentation. The approach typically appears designed to place the LLM in the most favorable light. In this case, it also highlights SQL generation capabilities. I am unaware of any other leading LLM provider that has published their results for the SQL generation benchmark Spider. However, this is central to Snowflake’s core product.
Interestingly, Snowflake recently announced its new SQL Copilot, powered by the Mistral Large LLM. In that case, it appears to also be using Arctic. The Copilot announcement included the statement, “Not only do we have a unique vantage point into the challenges faced by data analysts, we also possess rich metadata that feeds into Snowflake’s dedicated text-to-SQL model that Copilot leverages in combination with Mistral’s technology.”
Architecture
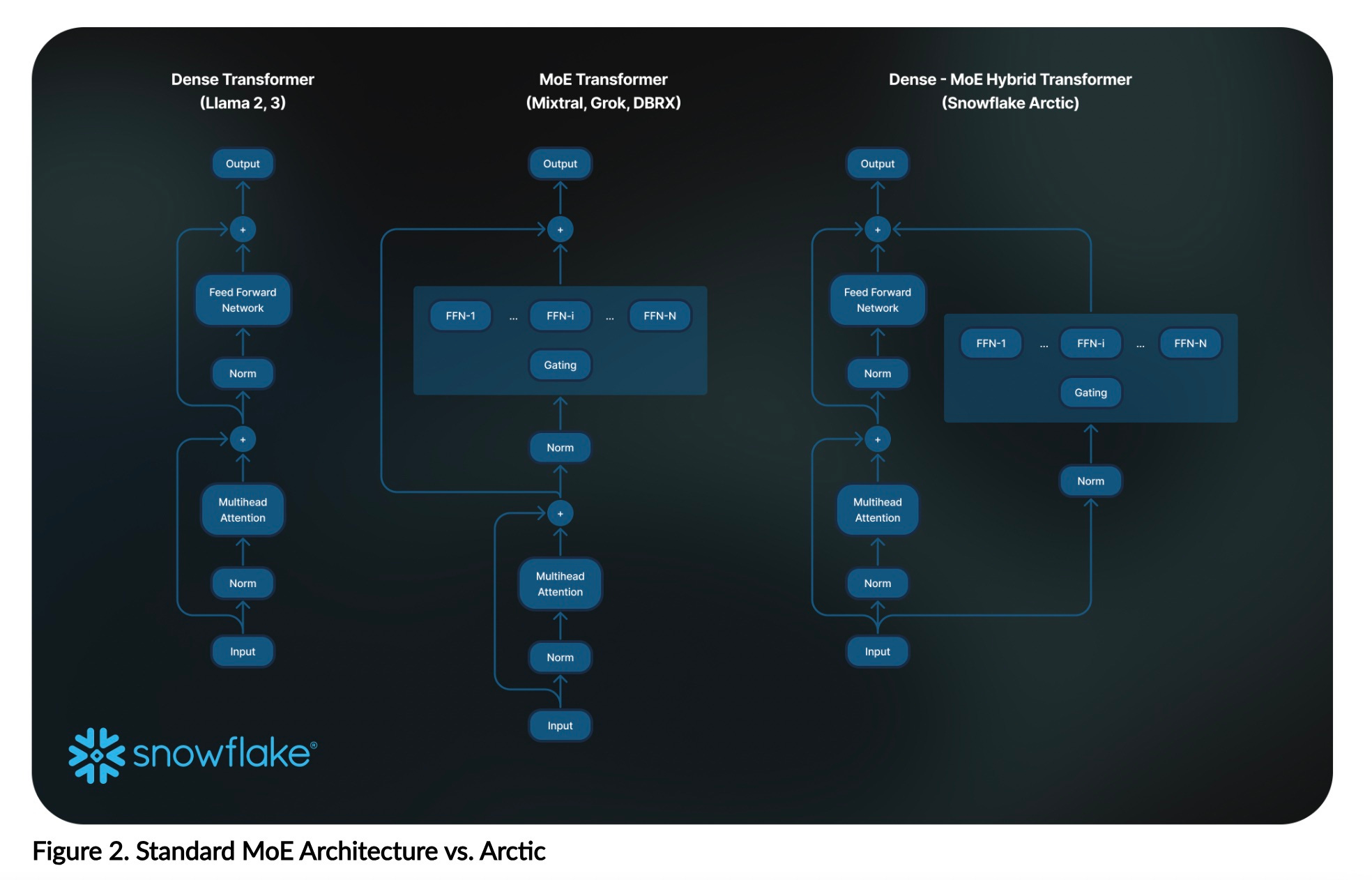
The most interesting information behind Arctic’s development is the modified MoE architecture which combined elements of both dense and MoE methods, combined with a novel training approach that segments training datasets by the type of knowledge.
Arctic uses a unique Dense-MoE Hybrid transformer architecture. It combines a 10B dense transformer model with a residual 128×3.66B MoE MLP resulting in 480B total and 17B active parameters chosen using a top-2 gating. It was designed and trained using the following three key insights and innovations:
1) Many-but-condensed experts with more expert choices: In late 2021, the DeepSpeed team demonstrated that MoE can be applied to auto-regressive LLMs to significantly improve model quality without increasing compute cost.
In designing Arctic, we noticed, based on the above, that the improvement of the model quality depended primarily on the number of experts and the total number of parameters in the MoE model, and the number of ways in which these experts can be combined together.
Based on this insight, Arctic is designed to have 480B parameters spread across 128 fine-grained experts and uses top-2 gating to choose 17B active parameters. In contrast, recent MoE models are built with significantly fewer experts as shown in Table 2. Intuitively, Arctic leverages a large number of total parameters and many experts to enlarge the model capacity for top-tier intelligence, while it judiciously chooses among many-but-condensed experts and engages a moderate number of active parameters for resource-efficient training and inference.
2) Architecture and System Co-design: Training vanilla MoE architecture with a large number of experts is very inefficient even on the most powerful AI training hardware due to high all-to-all communication overhead among experts. However, it is possible to hide this overhead if the communication can be overlapped with computation…
3) Enterprise-Focused Data Curriculum: Excelling at enterprise metrics like Code Generation and SQL requires a vastly different data curriculum than training models for generic metrics. Over hundreds of small-scale ablations, we learned that generic skills like common sense reasoning can be learned in the beginning, while more complex metrics like coding, math and SQL can be learned effectively towards the latter part of the training. One can draw analogies to human life and education, where we acquire capabilities from simpler to harder. As such, Arctic was trained with a three-stage curriculum each with a different data composition focusing on generic skills in the first phase (1T Tokens), and enterprise-focused skills in the latter two phases (1.5T and 1T tokens). A high-level summary of our dynamic curriculum is shown here.
Unsurprisingly, Snowflake leverages large training datasets that exceed three trillion data tokens. It is a data company, after all. However, the more interesting contribution to the industry is the test case of training based on a series of curated datasets.
Data curation has become a common theme of the newest LLMs introduced in 2024. However, the idea that model training efficiency and performance are correlated with the sequence of datasets employed in training has been explored less.
The hybrid model is not unique in LLM application deployments where smaller unified models are employed in parallel or at a specific point in the query processing along with a larger model. The smaller model typically performs a tightly bounded expert role in processing, such as moderation, whereas the primary model focuses on query interpretation and response. Snowflake’s implementation is novel in combining these processes in a single model.
This is not necessarily a stronger approach from an application standpoint. Employing separate models enables more refined use case specialization. However, Snowflake uses the approach to balance the tradeoff between performance and inference efficiency. It will be interesting to see if other LLM developers experiment with this approach going forward.
Data Platform Wars
While it may seem odd that Snowflake has chosen to compete with AI foundation model competitors, the strategy behind Arctic is less about OpenAI and Mistral and more about Databricks. The data platform providers want to ensure they maintain a central role in generative AI applications and do not become commoditized.
Databricks acquired MosaicML in early 2023. MosaicML was the creator of the MPT model that regularly topped benchmark performance leaderboards on Hugging Face. More recently, Databricks introduced the new DBRX LLM. Arctic is Snowflake’s answer to the LLM offering of its key rival in the data platform market.
It is unlikely that Arctic and DBRX will become more popular offerings than products offered by OpenAI, Google, Anthropic, and Mistral. However, it makes sense for the companies to create an easy onramp for their data platform customers to adopt generative AI solutions that lock in tighter use of their data software products.

Databricks Claims a Performance Lead with a New Open LLM

Databricks has announced a new open large language model (LLM) called DBRX that it says handily beats the Llama 2, Mistral, and Grok-1 open models in performance benchmarks. DBRX is a 132 billion parameter mixture-of-experts LLM trained on 12 trillion data tokens.
Mistral Has a New 176B Parameter LLM and a Number of New Customers

Mistral made a new large language model (LLM) available through a Tor link earlier this week, and it is now available through Hugging Face as well. The Mixtral 8x22B has a mixture of experts (MoE) architecture similar to the the Mixtral 8x7B model that debuted in December. However, the new model is larger in parameter count and context window size.
I’m fairly excited about what Databricks and Snowflake will become, and they realize AI is part of the their own customer funnel and retention.