



Accolades for OpenAI's GPT-4o Are Rising
The best benchmarks and the most user friendly

Since March 2023, every large language model (LLM) developer has been racing to catch up to OpenAI’s GPT-4. The performance gap was so wide enough that most of OpenAI’s rivals initially focused on simply matching, or slightly outperforming, GPT-3.5-turbo. Progress since late 2023 has accelerated, with many models surpassing GPT-3.5-turbo and Google and Anthropic claiming outright GPT-4 superiority. Of course, Google’s claim was for Gemini Ultra, which remains out of sight. What it really took to surpass GPT-4 was GPT-4o.
Multimodal and Less Expensive
GPT-4o is fully a multimodal model, which is why OpenAI calls it Omnimodel or “o.” This means that GPT-4o can take in and generate text, images, audio, and video. Most of the videos are tailored toward consumer-style ChatGPT use cases. However, the model enabling these can be applied directly to many enterprise use cases.
Among the many options, real-time language translation, image and video creation, video summarization and analysis, ingesting vision data into knowledge bases, and enabling voice interactions. Voice will likely be the most popular modality after text given the added convenience of speaking over typing and the large call centers maintained by many enterprises.
GPT-4o also arrived at a much lower price. It is $5/million tokens, compared to $30 for GPT-4 and $10 for GPT-4 Turbo, and $0.50 for GPT-3.5 Turbo. So, it is one-sixth of the GPT-4 base model and one-half of the Turbo. Even at that price, GPT-4o still costs 10x more than GPT-3.5 Turbo.
This suggests that a lot of enterprises will continue using GPT-3.5 Turbo, and nearly every company using GPT4 or the Turbo model will migrate to GPT-4o. It also means that several use cases that were previously not viable for the cost will now offer a practical price.
Benchmark Performance
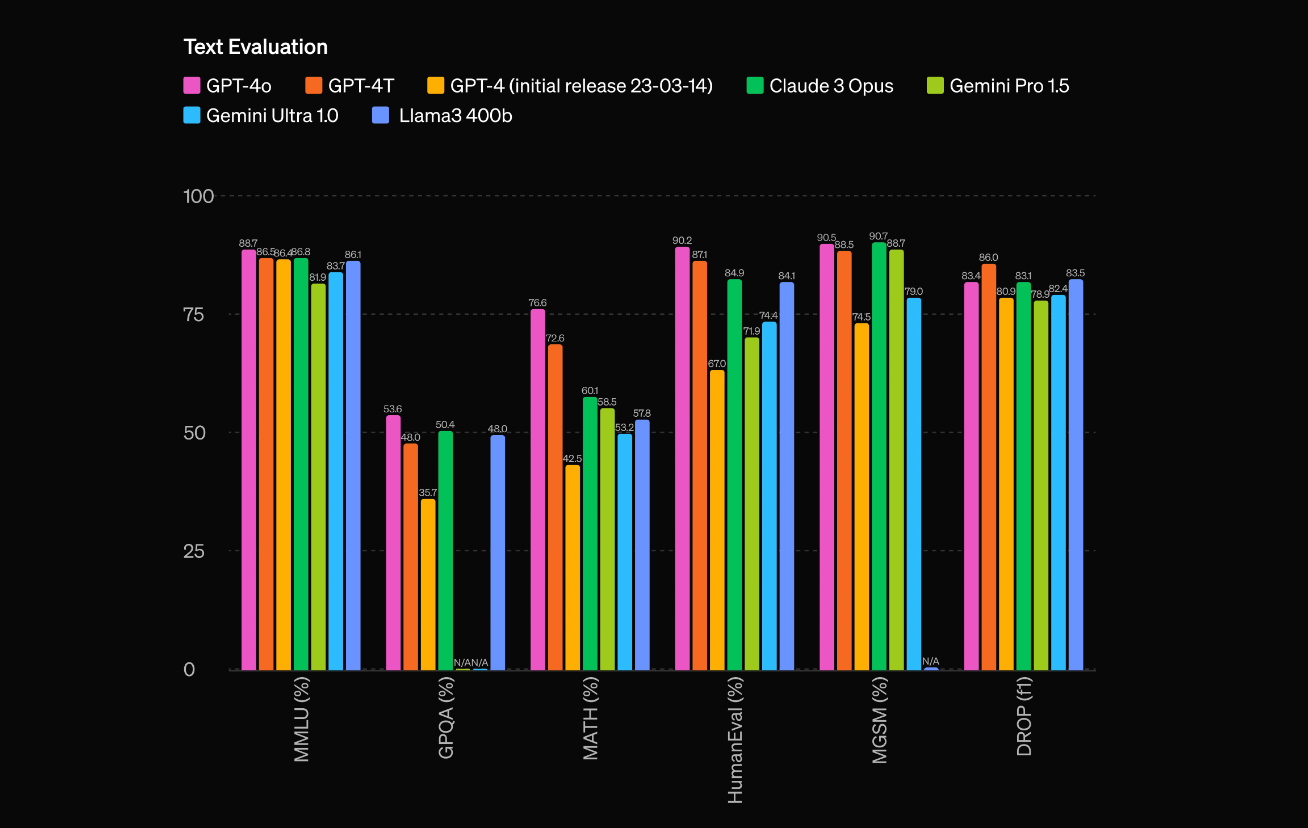
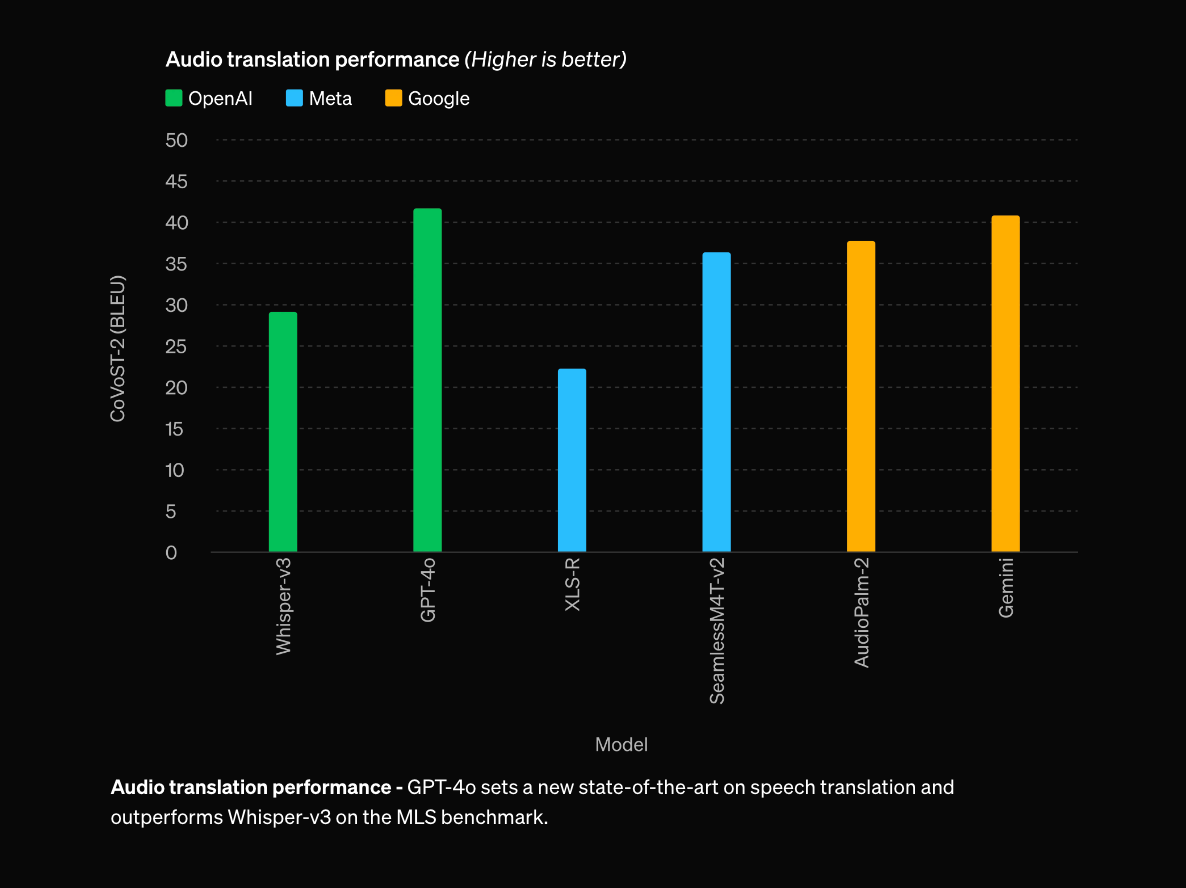
OpenAI’s latest Omnimodel has created quite an impression. Its MMLU results are slightly better than GPT-4, Claude 3 Opus, and Llama 3 400B and significantly better than rivals in MATH (mathematics and reasoning) and Vision. It also sets the pace in public benchmark results for audio translation, where, admittedly, few LLM providers have even attempted to compete.

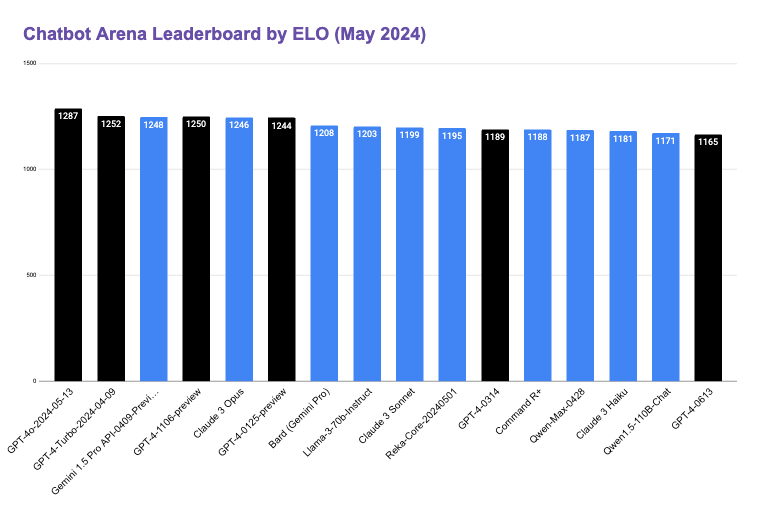
GPT-4o also landed at the top of the LMSYS Chatbot Arena Leaderboard. The leaderboard is based on pairwise comparisons by human testers. Note that GPT-4o debuted at the top, just ahead of the April edition of GPT-4 Turbo. Google Gemini Pro followed, then another GPT-4 version and Claude 3 Opus. OpenAI claims four of the top six spots. GPT-3.5 Turbo tied for 29th.
The figures above are the overall results. GPT-4o also bests it rivals in the subcategories where it has been tested. It is particularly stronger than other models in the coding category.
You may be interested that GPT-4o apparently did a test run on the LMSYS leaderboard under the name of gpt-2-chatbot, im-a-good-gpt2-chatbot, and im-also-a-good-gpt2-chatbot. In each instance it quickly shot to the top of the leaderboard before being removed. Techopedia reported:
In late April, a mysterious new chatbot known as “gpt-2-chatbot” emerged on the chatbot assessment site LMSYS.org. As soon as users discovered it, speculation began over whether this could be a new release from OpenAI.
It didn’t just have the same name as an older GPT-2 large language model (LLM) released by OpenAI; it also displayed performance that was on par with and, in some places, even exceeded proprietary models like GPT-4.
After a wave of interest, it was removed from the LMSYS.org website but returned this week as two models: “im-a-good-gpt2-chatbot” and “im-also-a-good-gpt2-chatbot”.
Sam Altman, OpenAI’s CEO, plays up memes about the company’s products and doesn’t discriminate between true and false when there is an opportunity to inject humor. During this period of the gpt2-chatbots, Altman posted on X:

OpenAI's strategy of gauging how human testers would rate it compared to alternatives was a good idea. We are likely to see other model makers try this in the future as well.
Examples
There are several video demonstrations. I recommend readers take a look at “Customer service proof of concept,” “Two GPT-4os interacting and singing,” “Math with Sal and Imran Khan,” and “Real-time translation.” There are also a number of examples visual examples. We mentioned, “3D object synthesis” (i.e., text-to-3D), “Text to font,” and “Visual Narratives - Robot Writer’s Block” in the ChatGPT-4o Synthedia post.
You should also check out “Text to Font,” “Lecture Summarization,” “Visual Narratives - Sally the Mailwoman,” "and “Photo to Character.”

The examples are helpful, particularly for understanding how the multimodal inputs and outputs work by modality and across modalities. GPT-4o is a significant update that cannot be characterized as an LLM.
What’s Next
GPT-5 is likely to be the next model. Many people think about GPT-4o as the 4.5 release, but it seems more like an early version of GPT-5 or a revised version of the optimized model code named Arrakis. GPT-4o is so competent that OpenAI just bought itself a significant amount of leeway in its GPT-5 launch schedule.
What’s really next is the market’s absorption of GPT-4o. The model offers better performance and lower inference costs, but the multimodality will offer a new twist for many customers and open up new use cases.
OpenAI just made the job of convincing enterprise buyers to choose an alternative much harder. Enterprise buyers and software developers want the best combination of price and performance. They also want optionality. The multimodal features in GPT-4o are more advanced than peer offerings. Even if a developer does not need all of the modalities now, it may in the future. And the sprint out ahead of Anthropic, Google, and Meta will provide confidence that OpenAI will consistently be on the leading edge of the market.

6 Things Announced at Google I/O, One That Mattered A Lot, and One Mystery

Google I/O 2024 offered AI developers many futures and few presents. Most of the interesting AI-related features and applications are not available yet, only in the U.S. or part of a limited-access developer beta. But there were a lot of announcements and some provocative demos.
