

AI21 Labs Debuts an Open-Source Model With High Token Throughput
Open-source SLM complements a proprietary LLM


AI21 Labs released an open-source model at the end of March, marking a new strategy for the Israeli company in terms of technology and market approach. Mamba is known as a structured state space model (SSM) architecture and Jamba combined this approach with a a transformer architecture. In addition, Jamba also adopted a mixture-of-experts (MoE) architecture where multiple smaller transformer models are combined to improve inference efficiency. So, Jamba offers a SSM+Transformer+MoE in what we might call a mixture-of-architectures (MoA) approach.
A Model Departure
Jamba reflects a departure from previous AI21 large language models (LLM), such as Jurassic, a unifed model using a transformer architecture. Earlier AI21 releases were also proprietary. Jamba is an open-source model with an Apache 2.0 license. This reflects a similar shift taken by Google when it released the Gemma models as small, open (though not technically open-source) and likely based on an MoE architecture. According to the AI21:
We are thrilled to announce Jamba, the world’s first production-grade Mamba based model. By enhancing Mamba Structured State Space model (SSM) technology with elements of the traditional Transformer architecture, Jamba compensates for the inherent limitations of a pure SSM model. Offering a 256K context window, it is already demonstrating remarkable gains in throughput and efficiency—just the beginning of what can be possible with this innovative hybrid architecture.
Key Features
First production-grade Mamba based model built on a novel SSM-Transformer hybrid architecture
3X throughput on long contexts compared to Mixtral 8x7B
Democratizes access to a massive 256K context window
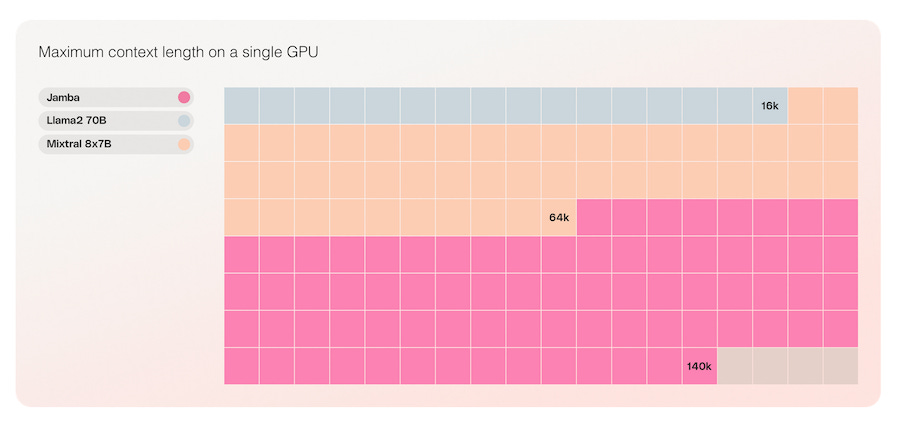
The only model in its size class that fits up to 140K context on a single GPU
Released with open weights under Apache 2.0
Available on Hugging Face and coming soon to the NVIDIA API catalog
The research paper accompanying the announcement offers additional context.
We present Jamba, a new base large language model based on a novel hybrid Transformer-Mamba mixture-of-experts (MoE) architecture. Specifically, Jamba interleaves blocks of Transformer and Mamba layers, enjoying the benefits of both model families. MoE is added in some of these layers to increase model capacity while keeping active parameter usage manageable. This flexible architecture allows resource- and objective-specific configurations…Remarkably, the model presents strong results for up to 256K tokens context length…The 7B-based Jamba model (12B active parameters, 52B total available parameters) we are releasing was designed to fit in a single 80GB GPU, but the Jamba architecture supports other design choices, depending on one’s hardware and performance requirements.
Performance
Because Jamba is an open-source model, AI21 chose to present benchmark performance data with comparisons to other open models, including Meta’s Llama 2 (13B and 70B), Google Gemma (7B) and Mixtral 8x7B. Jamba shows performance leadership in Hellaswag, WinoGrande, and PIQA. It is second in TruthfulQA and GSM8K, and third in Arc-C and MMLU.

Jamba’s performance also trails the open models Grok-1 and DBRX for MMLU and GSM8K performance. Granted, these are both larger models so you should expect better performance. The angle AI21 is taking is that adding the Mamba architecture can bring you close to the performance of larger MoE models while also delivering other benefits.
Speed and Cost Efficiency
The key differentiating benefits that AI21 is promoting are related to token generation speed for larger context windows and cost efficiency. While Jamba is comparable to Lama 2 70B and Mixtral 8x7B for small context windows, the speed becomes to diverge round 16k context windows and is three times faster than Llama 2 at 128k. This is significant if the use case requires long-context windows.

In addition, Jamba’s architecture enables a 140k context window on a single GPU compared to just 16k for Mixtral 8x7B and 64k for Llama 2 70B. Again, larger context window use cases may see some benefit. With that said, it is unclear whether there is a significant advantage for use cases with small context window requirements.
The Straddle Strategy
AI21 is positioning Jamba as a light, efficient open-source model with comparable or better performance compared to open-access small language models (SLM). This complements the company’s proprietary LLMs. It also reflects a straddle strategy. With offerings in the proprietary frontier foundation model category (Jurassic) and the open-source SLM category AI21 is hedging its bets (or increasing its options), similar to Google’s recent approach with the Gemma models.
AI21’s portfolio also extends into consumer applications with the Wordtune writing assistant, a Grammarly competitor. Google offers a general purpose assistant in Gemini Advanced, plus several solutions baked into its office productivity software. Of course, Google also has image and video generative models as well as a variety of speech generation, translation, and related services. Its offering scope is far larger. However, you can see some similarities in the approaches.
Offering a broader set of models in terms of capabilities and licensing options provides more choices for enterprises and more reasons to consider AI21. The portfolion approach also presents more opportunities for both AI21 and Google to test the market and see where demand materializes.

Databricks Claims a Performance Lead with a New Open LLM

Databricks has announced a new open large language model (LLM) called DBRX that it says handily beats the Llama 2, Mistral, and Grok-1 open models in performance benchmarks. DBRX is a 132 billion parameter mixture-of-experts LLM trained on 12 trillion data tokens.
Grok-1.5 Closes Gap with OpenAI, Google, and Anthropic, Aces Long Context Window Retrieval

X.ai announced the Grok-1.5 large language model (LLM) Thursday, and it reflects a significant performance and feature upgrade over the now open-source Grok-1 model. Caveats aside about what benchmark results LLM developers choose to present, MMLU, MATH, GSM8K, and HumanEval results rose from Grok-1 to Grok-1.5, from 73% to 81.3%, 23.9% to 50.6%, 62.9% …