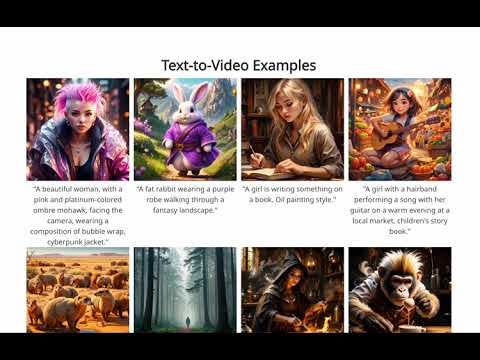
OpenAI's Sora Text-to-Video Demonstrations are Insanely Good
The solution is only available for red team testing, but may set a new quality standard

Earlier today, OpenAI debuted Sora, the company’s first text-to-video AI model. It is not yet available to the general public, but the announcement said it is going through testing. While the model supports a variety of styles, it clearly excels in photo-realism, as seen in the video embedded above.
ByteDance, Pika Labs, Runway, Stability AI, Meta, and others have also introduced or demonstrated impressive text-to-video capabilities, but Sora may set a new standard. According to the announcement:
Today, Sora is becoming available to red teamers to assess critical areas for harms or risks. We are also granting access to a number of visual artists, designers, and filmmakers to gain feedback on how to advance the model to be most helpful for creative professionals.
We’re sharing our research progress early to start working with and getting feedback from people outside of OpenAI and to give the public a sense of what AI capabilities are on the horizon.
Longer Videos
A particularly notable element of the demonstrations is their length. “Sora can generate videos up to a minute long while maintaining visual quality and adherence to the user’s prompt.” Most of the examples provided by OpenAI are between 8 and 20 seconds. However, their is a photorealistic 57-second clip of a woman walking down a on a Tokyo city street and a minute-long animated video of wolves. This duration is not something other text-to-video solutions have show, at least not at this resolution. Google did show off a video in excess of two minutes back in October 2022 using its Phenaki model, but the resolution was far lower.
Natural Prompts
Another element that stood out was the prompts. There is an art and science behind the prompt techniques employed to generate high quality images using Midjourney, Stable Diffusion, and DALL-E. Very often, it is the use of technical terms or specific nomenclature that make the difference. The prompts for most of the Sora examples are conceptual. No technical elements are required.
There likely will be reasons to use technical terms in prompts to nudge the videos toward the user’s vision. However, the first-time quality based on simple descriptive text is impressive.
Extending, Stitching and Filling in Videos
OpenAI also says that Sora is not limited to creating new videos from a prompt. The technical discussion goes into some depth about how the model can work when modifying existing videos and filling in gaps in video footage. This is a similar technique to inpainting employed by text-to-image models.
A video or an image can be part of a prompt used as an input. OpenAI also says the solution can project backward or forward in time based on a video input to create new footage. The 2D version of this in DALL-E would be outpainting. In fact, OpenAI researchers suggests that its models see a static image as a single frame video and can generate images in addition to video.
Safety and IP Protection
OpenAI’s announcement includes a substantial discussion around safety and IP protection. It is unclear why the company is debuting the technology in advance of its public release. This runs counter to OpenAI’s traditional practice. The change may reflect OpenAI’s higher visibility and therefore higher perceived risk associated with exposing errors publicly. It also may be that OpenAI wants to show the market what is coming before companies make commitments to building on a Stability AI, Runway, Google, or Meta model.
In addition to its current plans around red teaming and community feedback from creatives, OpenAI is also leveraging safety tools it built for DALL-E.
In addition to us developing new techniques to prepare for deployment, we’re leveraging the existing safety methods that we built for our products that use DALL·E 3, which are applicable to Sora as well.
For example, once in an OpenAI product, our text classifier will check and reject text input prompts that are in violation of our usage policies, like those that request extreme violence, sexual content, hateful imagery, celebrity likeness, or the IP of others. We’ve also developed robust image classifiers that are used to review the frames of every video generated to help ensure that it adheres to our usage policies, before it’s shown to the user.
The Technology
Sora is based on a diffusion model architecture, similar to DALL-E. Diffusion models begin by assembling a number of data points that look like random noise. Through a series of steps, the image is gradually refined and enhanced. For video, this is done multiple times for each frame.
OpenAI points out that the quality of the transformation of the text into video is largely a byproduct of improved training and data parsing techniques. Researchers adopted the tokenization approach used for large language model (LLM) training and created the visual equivalent which they refer to as patches. It also used a high fidelity captioning technique that observed the videos and appended that data into the training process. This likely led to much richer descriptions of videos and enables better concept matching between a prompt and visual imagery.
We take inspiration from large language models which acquire generalist capabilities by training on internet-scale data.13,14 The success of the LLM paradigm is enabled in part by the use of tokens that elegantly unify diverse modalities of text—code, math and various natural languages. In this work, we consider how generative models of visual data can inherit such benefits. Whereas LLMs have text tokens, Sora has visual patches. Patches have previously been shown to be an effective representation for models of visual data.15,16,17,18 We find that patches are a highly-scalable and effective representation for training generative models on diverse types of videos and images.

This really just scratches the surface. The technical paper is now hosted on OpenAI’s website where you can find far more detail. It includes a discussion of the simulation environments that Sora can create and some of its shortcomings.
Sora currently exhibits numerous limitations as a simulator. For example, it does not accurately model the physics of many basic interactions, like glass shattering. Other interactions, like eating food, do not always yield correct changes in object state.
The information and videos shared are impressive. Granted, the claims have not yet had to stand up to critical use by consumers in the wild. We can be certain there will be issues and limitations. However, despite all of the impressive text-to-video demonstrations we have seen previously, Sora still managed to stand out as frontier quality technology.