

Inflection Reveals a New Model Rivaling GPT-4, Pi Daily Users, and Different Assistant Strategy
Straddling the Assistant-Companion Divide

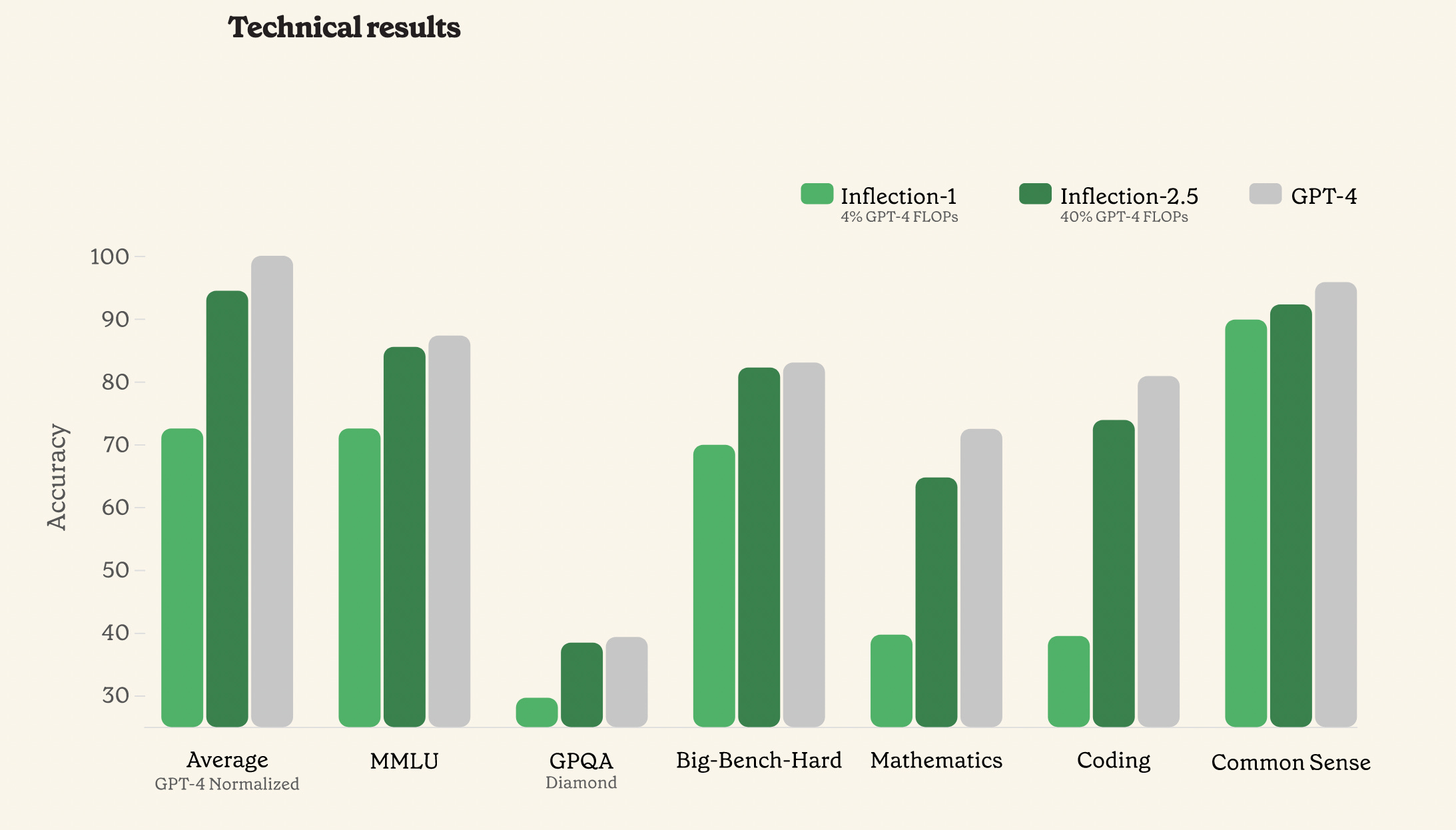
Inflection has announced its new large language model (LLM), Inflection 2.5. The company’s self-reported benchmark results show that Inflection 2.5 is nearing the performance of OpenAI’s GPT-4. This is among several recent announcements claiming equal or superior performance to GPT-4, which has generally been viewed as the leading generative AI model available.
Google and Athropic say Gemini Ultra and Claude 3, respectively, beat GPT-4 on several and potentially most standard LLM benchmarks. Inflection claims that 2.5 beat GPT-3.5 and is very close to GPT-4. For most use cases today, surpassing GPT-3.5 is probably more than sufficient.
Inflection also took the opportunity to announce some user statistics from its personal assistant, Pi. While Pi doesn’t come close to OpenAI’s ChatGPT or Perplexity in terms of user adoption, it has captured some growth and meaningful usage.
Presenting Model Performance
Inflection selected a number of commonly used public benchmarks to compare the 2.5 model with GPT-4. The chart above references three specific benchmarks, such as MMLU and Big-Bench-Hard, and three capability categories that represent multiple benchmarks. For example, the Common Sense category is based on combined results from HellaSwag and ARC-C 25 shot.
It is important to keep in mind that some of these benchmarks, such as Hellaswag, MMLU, and GSM8k are single benchmarks, ARC and others have variants. So, any side-by-side comparison needs to consider which are selected. In addition, Microsoft, Inflection, and others now often combine multiple benchmarks into categories. When this is done, it can be hard to understand how the models performed on each model, as the intent is to show aggregated performance comparison. This clustering of benchmarks does provide value to researchers, but it also presents the opportunity to improve the optics of the performance results based on singular or grouped results.
You see this when digging deeper into the Inflection data. The Mathematics category is comprised of the GSM8k and MATH benchmarks. Inflection 2.5 is within 10% of the reported GPT-4 performance. However, Inflection 2.5 uses 8-shot GSM8k and 0-shot MATH benchmarks, while GPT-4 data is for SFT+5-shot-CoT and 4-shot, respectively. It could be that Inflection is actually outperforming GPT-4 or vice versa. Just keep in mind these benchmarks are similar but not identical and could be misleading.
You will also see different benchmarks presented across model generations. For example, Inflection 2.0 reported results for ARC-C 1 shot while 2.5 shows ARC-C 25 shot. Why? The 2.0 model also provided results for TrivaQA and PIQA benchmarks, while these are noticeably absent from the 2.5 model benchmark data. Again, why?
One obvious difference is that the 2.0 model compared Inflection to Google PaLM, a significantly inferior model to GPT-4. Comparing GPT-4 would not have provided the right optics. Instead, Inflection compared a model that even Google was not encouraging developers to use. Now that Inflection is more confident about its GPT-4 comparison, it is providing that reference.
It is fair to say that Inflection 2.5 is stronger than the 1.0 and 2.0 versions. It is also closer to GPT-4. However, you should also view the presentation of this data as only partially expressing information about model performance and comparison. It also expresses, and sometimes mostly focuses on, how the company wants you to perceive its model. The one constant today is that everyone recognizes that OpenAI’s GPT-3.5 is the most widely used model, and GPT-4 has been known as the best-performing model.
To be clear, Inflection is not alone in applying these practices. Every foundation model developer does this to some extent. Researchers are also learning what benchmarks matter in real-time, which surely accounts for some of the variances along with the limited availability of data for rival foundation models. It is simply worth noting that what you intuitively think may be happening is actually happening in the presentation of LLM benchmarks. The comparisons are not as clear-cut as the model developers present them.
Inflection’s proposed narrative is that its models now approach GPT-4 in performance but consume far less compute during training. There is a clear claim about efficiency, but it is less clear why a model user should care since they access the model after training is complete. More importantly, the new model supports Inflection’s primary product, the virtual assistant Pi, and that will presumably improve its performance.
Inflection-1 used approximately 4% the training FLOPs of GPT-4 and, on average, performed at approximately 72% GPT-4 level on a diverse range of IQ-oriented tasks. Inflection-2.5, now powering Pi, achieves more than 94% the average performance of GPT-4 despite using only 40% the training FLOPs. We see a significant improvement in performance across the board, with the largest gains coming in STEM areas.
…
These results show how Pi now incorporates IQ capabilities comparable with acknowledged industry leaders… In short, Inflection-2.5 maintains Pi’s unique, approachable personality and extraordinary safety standards while becoming an even more helpful model across the board.
The Good Enough Threshold
That said, the maniacal focus on GPT-4 comparisons may be overwrought. All engineers want to show that their work compares well with the frontier foundation models. However, in practice, this is often not a deciding criterion.
For example, GPT-3.5 is more widely used than GPT-4 due to cost and latency considerations. All else being equal, the companies using GPT-3.5 would switch to GPT-4. GPT-3.5 is good enough for many applications so it makes sense to save cost and provide a more user-friendly experience with snappy responses. Companies considering models based on benchmarks or in-house testing are intuitively or explicitly making these trade-offs. However, this line of reasoning doesn’t show up in most of the AI company blog posts. I expect that to change over time.
AI model developers who want to become an alternative to OpenAI must consider whether they are shooting for that distinction in relation to GPT-3.5, GPT-4, or both. At a market level, the important point is that the frontier models will carry the headlines and awestruck user responses, but the “good enough” models will likely drive the most revenue. OpenAI today has the advantage of leadership in both of those categories, though the frontier category may be in question until GPT-4.5 or GPT-5 launch.
The Rise of Pi
Along with the improvement in model performance, Inflection also shared new data about Pi adoption. The total user adoption figures are modestly positive, though not nearly strong enough to show clear momentum. By contrast, the user behavior is intriguing.

The 33-minute average session length and 10% that last more than an hour suggest robust usage, while the 60% week-over-week retention rate indicates user loyalty. According to SEM Rush data, the session length data for Character AI fluctuated between 25 and 40 minutes in 2023. By contrast, data from 2023 showed ChatGPT users were typically using the service for 8 to 10 minutes at a time. It may be that the appropriate comparison set for Pi is Character AI more than ChatGPT.
Both Inflection and Character AI provide users with the opportunity to create personal companions. These are the types of use cases that drive long user sessions and frequent use. In addition, both services provide some similar feature capabilities to ChatGPT but are fundamentally differentiated as companions or entertainment as opposed to productivity tools.
Grok is likely to follow a similar path. Part entertainment, part companion, and part productivity assistant, but leaning more to the latter. The question is whether straddling several use cases and mental models will be viewed as an asset or simply suboptimizes across the models.
Memory, EQ & Empathy
Inflection nominally competes with OpenAI. Both have LLMs and offer APIs for access. Both have chat-based assistants that help users with daily tasks. Inflection differentiates Pi from ChatGPT by adding personalization. Whereas ChatGPT excels in IQ (intelligence quotient), Inflection has stressed Pi’s EQ (emotional intelligence quotient) up until the most recent model release. It now says that Pi has both.
That seems like a nice differentiation. Granted, ChatGPT is now experimenting with memory so OpenAI’s assistant can retain information about the user and better tailor the experience. Memory is not equivalent to EQ, nor is it a requirement. Some people have a very high EQ that can be applied even to people they have just met. The impact of EQ can be heightened with context that could come from shared memory or simply from knowledge of the other person, their situation, or environment.
So, when Inflection says Pi has a high EQ, they typically use it as a shorthand for personalization. Memory is critical for personalization. Other generative AI assistants, as well as most voice assistants, lack memory. By starting with memory, Pi began with a personalization advantage.
This personalization feature is a likely reason behind the 33-minute average session length and the fact that 10% of sessions last more than an hour. It also indicates that Pi users are probably treating it as a companion in addition to a virtual assistant where sessions times would typically be shorter. The models behind these assistants could also be tuned to express more empathy and seem more humanlike, but we are mostly talking about personalization more than EQ.
Virtual Companions
Pi is positioned as the virtual companion that also has knowledge. ChatGPT is the knowledge assistant that probably will not morph into a companion. It will have more personalization, but that will align with goals for productivity and convenience more than for companionship.
“A.” (pronounced “a dot”) is the virtual companion offered by SK Telecom. It launched pre-generative AI but includes memory, personality, and conversational interactions. Last year, SK Telecom added an OpenAI LLM to provide it with more intelligence. Like Pi, “A.” began as a companion and added more IQ. According to a CNBC report:
“Through these conversations, users can share information about their daily life like they are talking to a close friend,” SKT said in a press release.
SKT has tried to position A. as a different proposition to ChatGPT. A. has a number of cartoon avatars that users can interact with. SKT said it has brought more AI agents named “A. friends” to the product, equipped with conversational AI technology “that enables emotional and human-like conversations.”
“By engaging in conversations with ‘A. friends’, users can receive counseling and advice on a wide variety of topics,” SKT said.
GenAI Virtual Assistants
ChatGPT is not positioned as a companion. It’s a productivity tool. Character AI is variously used for entertainment and companionship, though it can provide productivity features. Perplexity is essentially the opposite of Character AI in that it is a specialty assistant, completely focused on productivity for research. Grok is most similar to ChatGPT but not as focused on hardcore productivity. Pi is straddling the companion-productivity divide.

These products show how the assistant landscape is changing and highlight the fact that side-by-side comparisons are unlikely to explain their market approach or serve as a measure of market success. Products are slotting into specialty assistant, general purpose assistant, virtual companion, and virtual character segments. Pi is an anomaly in that it is actively focused on more than two of the segments in the generative AI assistant-companion spectrum.
When considering Inflection’s announcements this week, the story around Pi is much more compelling than the updated model. However, that could change. Pi is a product, but the model behind it could become a popular white label solution for third-parties to launch their own generative AI assistants. The broader spectrum of capabilities should serve the company well in that regard.

Why Perplexity is Already a Unicorn

Perplexity announced $74 million of new funding in January and a $520 million valuation. The Wall Street Journal reported last week that the company is on the cusp of a new funding round that will double its value to over $1 billion. Perplexity is growing fast. The company recently surpassed $10 million in annual revenue, a person familiar with the matt…
Anthropic Says it Just Dethroned GPT-4 from Atop the Frontier Generative AI Model Rankings

Anthropic’s Claude 3 model family launched today, along with data suggesting it is the first large language model (LLM) with superior performance to OpenAI’s GPT-4 across ten public AI model benchmarks. The product introduction includes the Opus, Sonnet, and Haiku models in descending order of performance and cost. Presumably, this also represents model…