



Meta Llama 3.1 405B May Spark a Tectonic Shift in the LLM Market Adoption
The open model that is taking on proprietary models for market leadership


The large language model (LLM) market has experienced several noted upheavals in 2024. New models have emerged to challenge OpenAI’s unmatched quality supremacy of 2023 to the point where there are several leading foundation models that can legitimately claim to be “market-leading.”
Google Gemini 1.5 introduced an industry-leading 1 million, then a 2 million token context window along with public LLM benchmark scores nearing OpenAI’s leading models.
Anthropic’s Claude 3.5 Sonnet showed public benchmark results that beat those of OpenAI’s GPT-4.
OpenAI introduced GPT-4o, the latest multi-modal AI foundation model demonstrating industry-leading performance across numerous benchmarks.
The result is greater user choice of AI frontier models. Frontier models are the LLMs and multimodal AI models that include the most impressive features, quality, and benchmark performance results. To date, this category has been dominated by proprietary models. Meta’s Llama 3.1 405B deserves recognition as the first open model to join the elite frontier model category. The implications are significant.
From Niche Leader to Overall Competitor
Meta made headlines in 2023 when it introduced the first Llama 2 70B model. It did not deliver the same performance as GPT-4, the leading model at the time. However, it was the most impressive LLM in the open model category, which meant it was free for nearly anyone to use—provided the developer could set up the servers, manage the installation, and pay some fairly hefty cloud computing bills.
With the July 2023 release, Meta carved out a leadership spot in the open LLM category. Offerings from X.ai, Databricks, and TII sought to challenge Meta’s leadership throughout late 2023 and into 2024. Meta reasserted its clear open model leadership credentials with Llama 3 early this year.
Llama 3.1 405B moves Meta up a notch. It retains and extends Meta’s lead in the open model category. The new release also places Meta among the leaders in frontier LLMs alongside OpenAI, Anthropic, and Google. This is particularly noteworthy when considering findings from a16z research earlier in 2024.
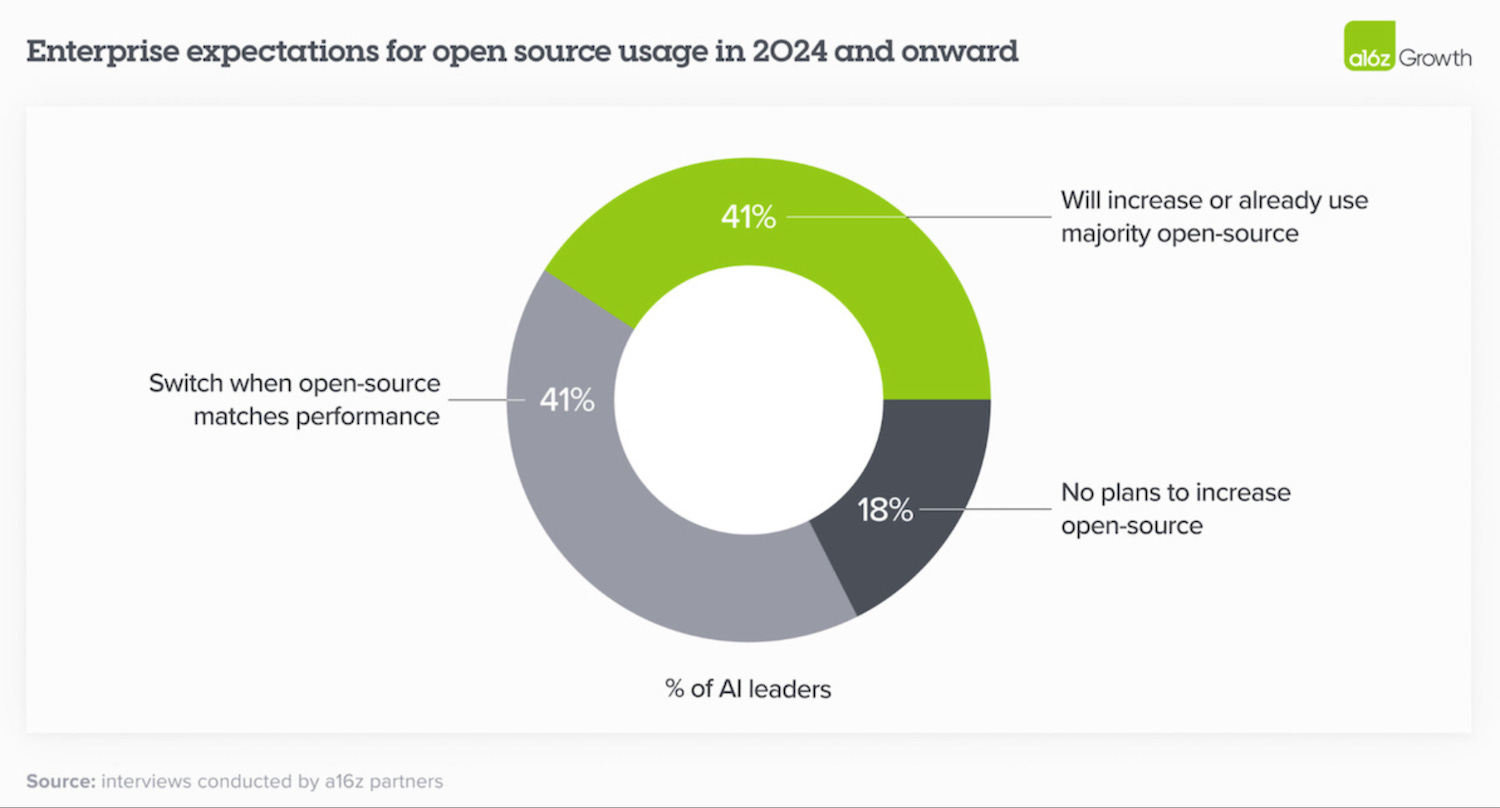
Forty-one percent of enterprises that have already deployed generative AI expect to increase the adoption of “open-source” models when they match performance with the leading proprietary models. Llama 3.1 405B will put that sentiment to the test. Comparable performance has arrived.
Leveled Up Performance
The evidence of Llama 3.1 405B’s performance rise can be seen in its improved scores on popular public LLM benchmarks. Its MMLU scores surpass GPT-4 and nearly match GPT-4o and Claude 3.5 Sonnet. Llama 3.1 also showed standout performance in reasoning, math, and long-context benchmarks.
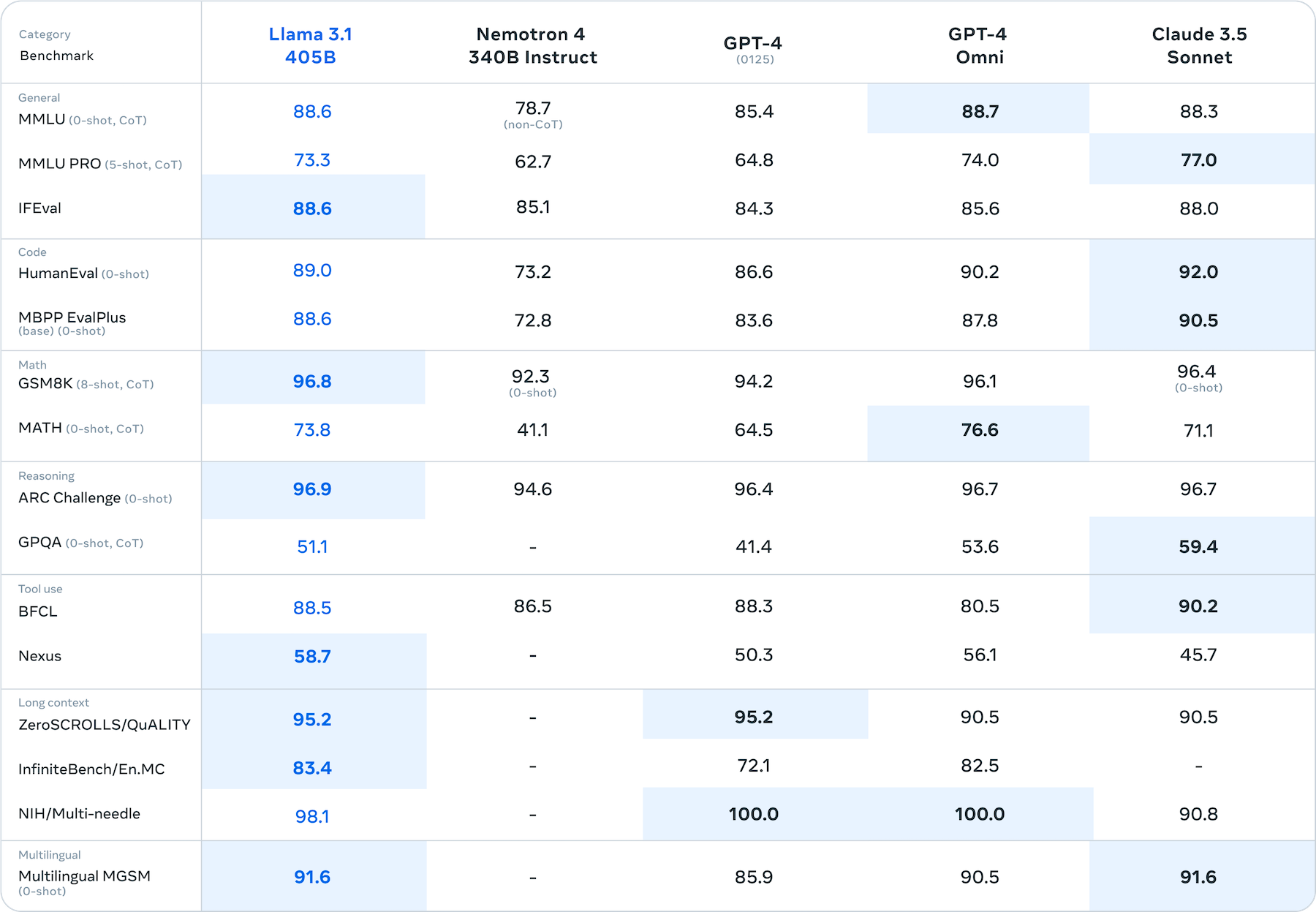
Comparing LLMs based on public benchmarks can be useful but doesn’t necessarily tell users the entire story of model performance. Model developers selectively publish benchmark results, and strong results for a handful of tests don’t necessarily translate into an optimal selection for a specific use case. Still, the benchmarks represent objective analyses of quality that users can consult before implementing or testing a model.
A key reason the 405B model performs so well is the data volume and quality used in training. It was trained on 15 trillion tokens. The new model also provides a 128K context window, which is sufficient for most use cases today. A research paper outlining the new model capabilities offered additional details on the impact of data.
Compared to prior versions of Llama, we improved both the quantity and quality of the data we use for pre-training and post-training. These improvements include the development of more careful pre-processing and curation pipelines for pre-training data and the development of more rigorous quality assurance and filtering approaches for post-training data. We pre-train Llama 3 on a corpus of about 15T multilingual tokens, compared to 1.8T tokens for Llama 2.
Excelling in Small Packages
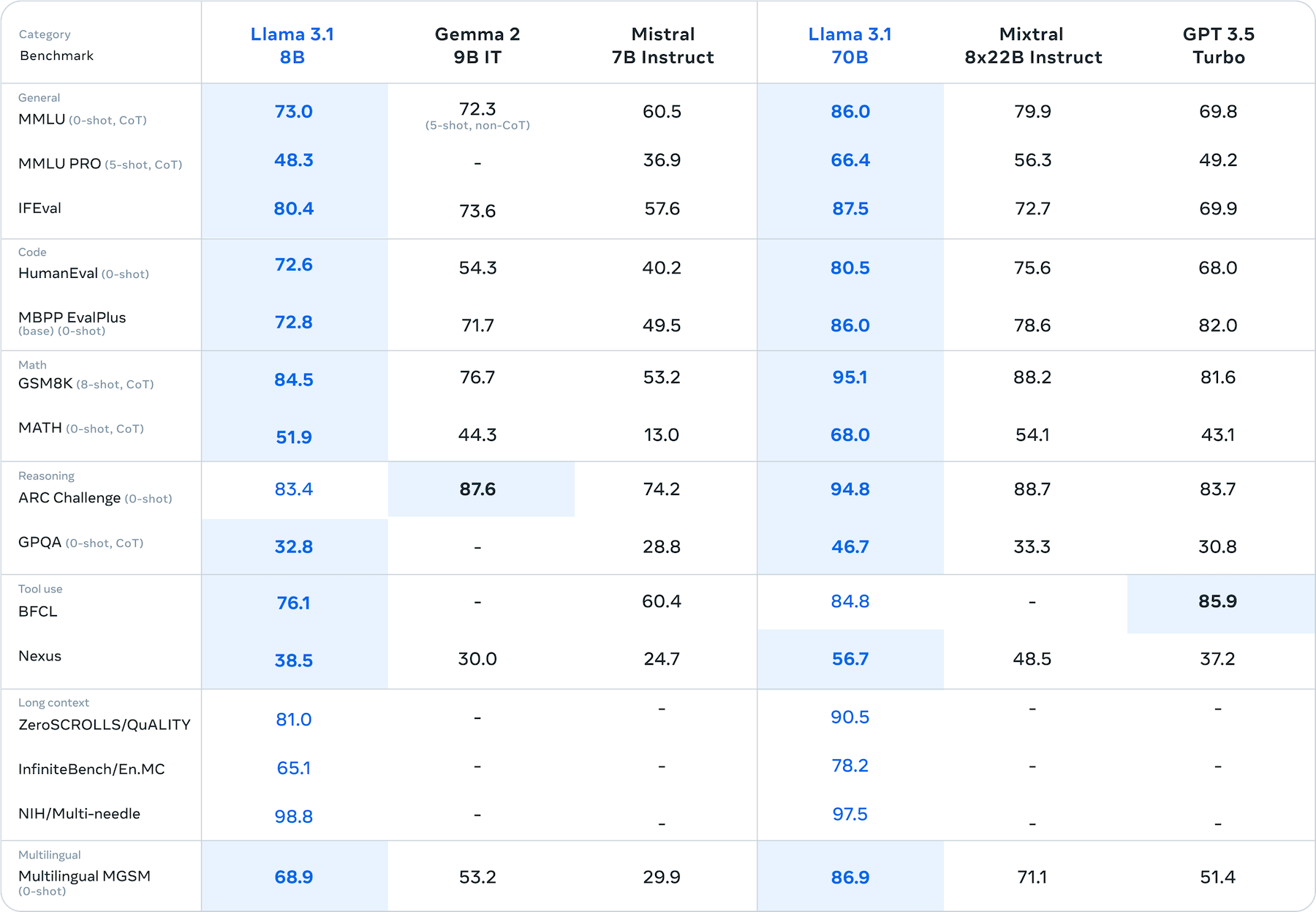
For developers considering smaller models, the Llama 3.1 series also includes the 70B and 8B (B = billion parameters) model sizes. The 70B model handily outpaces GPT-3.5 Turbo, and 8B shows a similar lead over Mistral 7B Instruct.
Broad Availability
A key drawback of many open models is that they are not widely supported as end-points. That means users need to deploy the models and manage the infrastructure in order to run inference jobs. However, that is slowly changing for open-source overall and has rapidly changed for Llama. Meta announced ten partners hosting Llama 3.1 405B models today. All of them offer real-time inference, over half provide batch inference, and all but one offer knowledge bases and guardrails.

High performance coupled with ease of access is critical for market penetration. Llama has generated a lot of enterprise interest, but there have been barriers to trial. The latest release shows that Llama 3.1 smartly adds more options for users to access the models, including those from each of the three leading cloud hyperscalers.
Open Leadership?
Meta CEO Mark Zuckerberg highlighted the market shift that Llama 3.1 405B represents in a blog post announcing the new models.
Today we’re taking the next steps towards open source AI becoming the industry standard. We’re releasing Llama 3.1 405B, the first frontier-level open source AI model, as well as new and improved Llama 3.1 70B and 8B models. In addition to having significantly better cost/performance relative to closed models, the fact that the 405B model is open will make it the best choice for fine-tuning and distilling smaller models.
Will this lead to a shift away from proprietary AI models? I don’t think so in the near term. However, there is strong interest among enterprise buyers for models that are frontier-grade and also open. Unsurprisingly, enterprises like the idea of asserting further control over their AI solutions along with enhanced privacy. Meta’s Llama 3.1 “Herd of Models” will likely be the catalyst that drives more enterprise trials of open models.
Many thanks to our title sponsor.
OpenAI Doubled Revenue and is Doing More Business Than Azure - New Reports

OpenAI’s generative AI market leadership has converted to solid revenue and customer growth. Recent reporting by The Information revealed that CEO Sam Altman told company employees “OpenAI has more than doubled its annualized revenue to $3.4 billion in the past six months or so.”
Anthropic Sonnet 3.5 Sets New Benchmark Standards

Anthropic released a new AI foundation model today. Claude 3.5 Sonnet is the latest iteration of the large language model (LLM) that has morphed into a multimodal AI model that includes capabilities around language and images. The new offering arrived less than four months after the introduction of the Claude 3 model family, which was among the first to…
Meta Llama 3 Launch Part 1 - 8B and 70B Models are Here, with 400B Model Coming

Meta launched the Llama 3 large language model (LLM) today in 8B and 70B parameter sizes. Both models were trained on 15 trillion tokens of data and are released under a permissive commercial and private use license. The license is not as permissive as traditional open-source options, but its restrictions are limited.
As a leader in the open-source large model community, LlaMA has evolved from version 1.0 to 3.1, benefiting countless developers and startups. Many vertical large models are trained or fine-tuned based on LlaMA. As Meta's CEO Zuckerberg said: "Open source is the direction of AI's progress."